人工智能(AI)在微生物组中的应用-随机森林分类与回归预测
机器学习或者人工智能(AI)是当前计算机领域研究的热点。然而,最近越来越多的研究者开始尝试将 AI 应用于另一个热门领域——微生物组研究。那么利用 AI 分析微生物组数据都做出了什么新结果呢?
1.微生物组或可预测人的实际年龄(南昌大学徐振江)
mSystems——[IF:6.519] Human Skin, Oral, and Gut Microbiomes Predict Chronological Age 02-12, doi: 10.1128/mSystems.00630-19
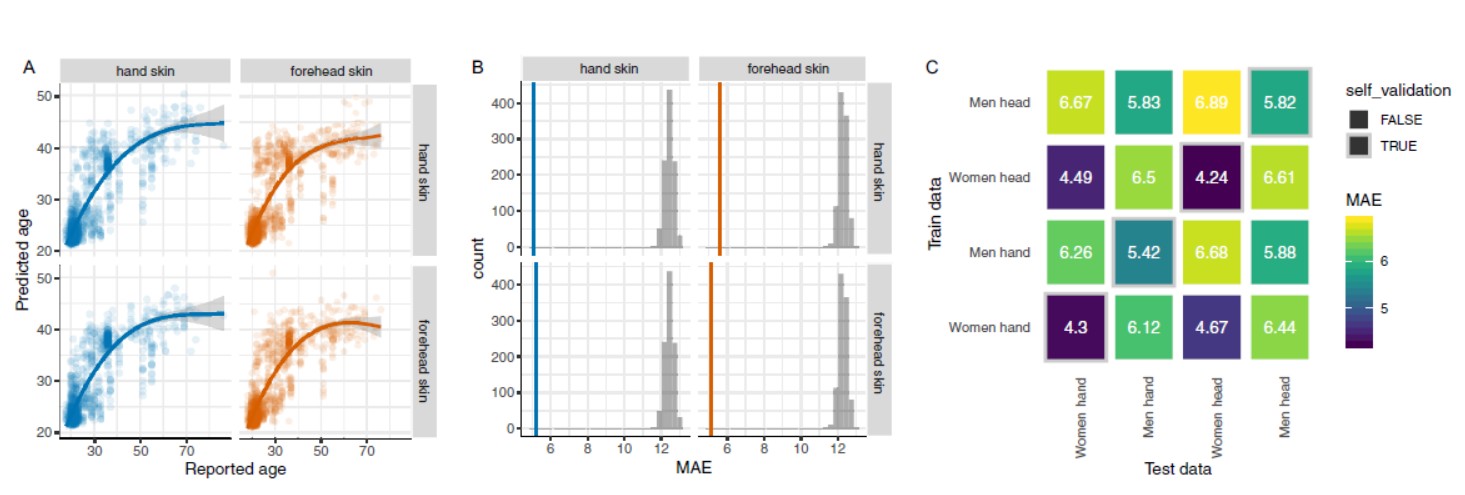
作者结合公开数据,用随机森林建立预测模型,评价粪便、唾液及皮肤(手和前额)样本微生物组预测成年人年龄的能力:其中皮肤微生物组可提供最佳的年龄预测(mean±SD为3.8±0.45年,口腔和肠道微生物组年龄预测mean±SD分别为4.5± 0.14和11.5 ±0.12年);多个批次研究均表明肠道微生物组与实际年龄有关; 手微生物组年龄预测模型可应用到前额微生物组年龄预测,反之亦然;与老年人富集的细菌相比,年轻人富集的细菌,丰度更高,且在多个群体中普遍存在。
2.NBT:随机森林准确预测籼粳稻亚种(白洋团队)
*NRT1.1B is associated with root microbiota composition and nitrogen use in field-grown rice
Nature Biotechnology [IF:35.724]
DOI:https://doi.org/10.1038/s41587-019-0104-4
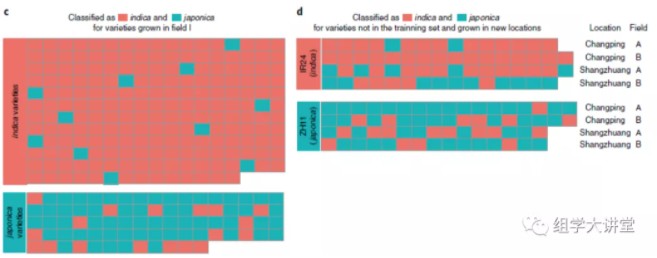
作者采用机器学习的随机森林方法,利用地块II中的微生物组数据,在门、纲、目、科、属和OTUs层面分别建立预测模型,其中在科水平判别的准确率高达83.7%。用该模型预测地块I的样品预测准确率为86%,其中籼稻预测准确率为94.5%,粳稻的准确率为77.5%(图c)。为了进一步验证模型的普适性,作者在距离海南陵水农场2,482公里外北京的两个农场(昌平和上庄)种植的水稻品种IR24(籼稻)和ZH11(粳稻)进行预测,这些品种不包括在海南种植的95个品种中,结果仍然较为准确(图d)。以上结果表明,根系微生物可以作为生物标记来区分籼粳稻亚种。

3.20个微生物组成可预测婴儿肠道微生物年龄
美国贝勒医学院:nature[IF=43] https://doi.org/10.1038/s41586-018-0617-x
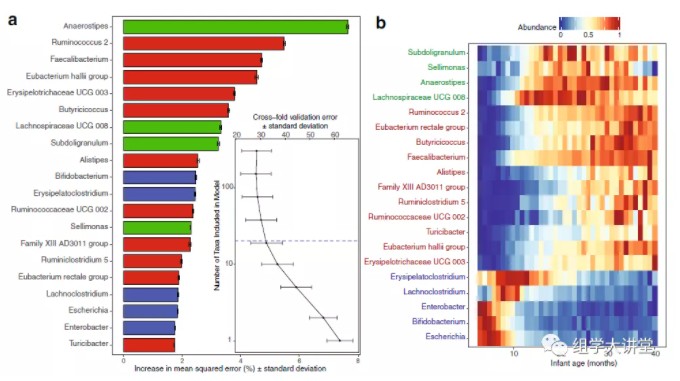
该研究随机选择150名足月、阴道分娩、母乳喂养的婴儿,每个婴儿至少10个样本,共2,871个粪便样本,通过R包“randomForest”建立肠道菌群与婴儿年龄的随机森林回归模型(random forest regression model),最终找到了20个与婴儿年龄相关的重要OTU。上图a,通过交叉验证筛选了20个显著的OTU。上图b,热图展示这20个物种平均相对丰度随着婴儿年龄的变化趋势。总结上面的三篇文章都用到了机器学习中的随机森林方法, 随机森林是机器学习的一种。利用随机森林分析可以帮我们找到数据中重要的特征:在微生物组中就是那些微生物组成可以作为特征进行各种预测;另外,随机森林可以利用这些重要特征构建模型用于分类预测(分类变量)或者回归预测(数值型变量);
4.深入了解随机森林
随机森林(random forest)是一种组成式的有监督学习方法,可视为决策树的扩展。随机森林通过对对象和变量进行抽样构建预测模型,即随机生成多个决策树,就像他的名字,并依次对对象进行分类。最后将各决策树的分类结果汇总,所有预测类别中的众数类别即为随机森林所预测的该对象的类别,分类准确率提升。
 要理解随机森林我们先来理解一下决策树(Decision Tree):在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。分类树(决策树)是一种十分常用的分类方法。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来做预测。
要理解随机森林我们先来理解一下决策树(Decision Tree):在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。分类树(决策树)是一种十分常用的分类方法。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来做预测。
例如下面就是一个决策树:你想买一套房子,但是你不知道怎么买,但是你可以根据一些条件做出决策:例如 价格,地点,停车位等等。
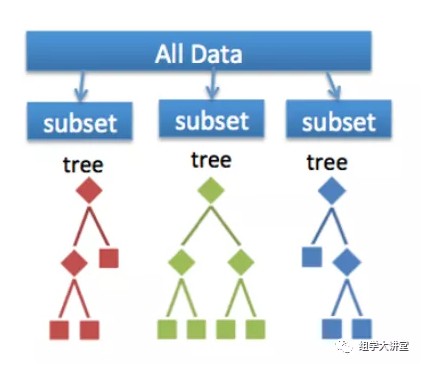
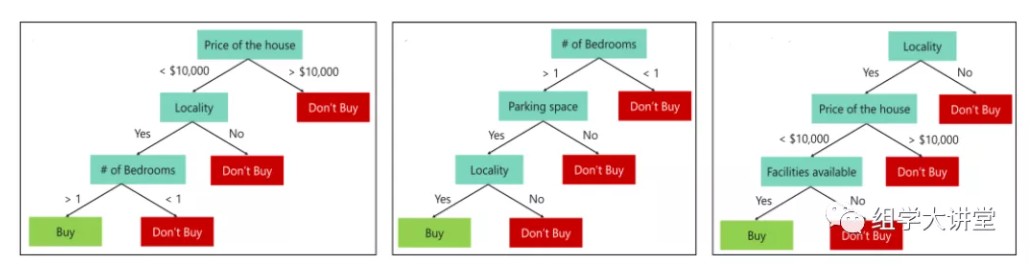
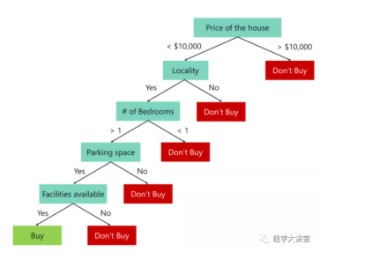 以上可以看出,决策树是根据整个预测数据得到的一个预测模型,而随机森林是由很多这样的决策树组成,每一个决策树用了三个不同的预测变量(下图所示),那么这种方法有什么好处呢?这种方法可以避免过拟合(overfiting):为了得到一致假设而使假设变得过度复杂称为过拟合(overfitting),过拟合表现在训练好的模型在训练集上效果很好,但是在测试集上效果差。
以上可以看出,决策树是根据整个预测数据得到的一个预测模型,而随机森林是由很多这样的决策树组成,每一个决策树用了三个不同的预测变量(下图所示),那么这种方法有什么好处呢?这种方法可以避免过拟合(overfiting):为了得到一致假设而使假设变得过度复杂称为过拟合(overfitting),过拟合表现在训练好的模型在训练集上效果很好,但是在测试集上效果差。
4.1随机森林工作过程可概括如下:
随机森林分析一般将数据分成两组,一组用于构建模型,一组用于验证模型的准确性。最关键的是构建模型,这里以微生物数据为例给大家总结如下:
假设训练集中共有N个样本 M个物种,想要用物种的丰度信息预测某个指标(如上面介绍的文献,年龄?,籼稻还是粳稻?)。
(1)首先训练集中随机有放回地抽取n个样本构建决策树n;
(2)在每一个节点随机抽取m个物种(m<M),将其作为分割该节点的候选物种,每一个节点处的物种数应一致;
(3)重复(1)-(2)过程,获得大量决策树;这个过程称之为:bootstrap aggregating(bagging)。
(4)利用Out-Of-Bag(OOB)方法检验所有决策树投票权重及评估决策树的准确度。oob error = 被分类错误数 / 总数
(5)对于测试数据集,用所有的树对其进行分类,其类别由多数决定原则生成。
微生物扩增子分析课程推荐:微生物扩增子分析课程实操
更多生物信息课程:
1. 文章越来越难发?是你没发现新思路,基因家族分析发2-4分文章简单快速,学习链接:基因家族分析实操课程、基因家族文献思路解读
2. 转录组数据理解不深入?图表看不懂?点击链接学习深入解读数据结果文件,学习链接:转录组(有参)结果解读;转录组(无参)结果解读
3. 转录组数据深入挖掘技能-WGCNA,提升你的文章档次,学习链接:WGCNA-加权基因共表达网络分析
4. 转录组数据怎么挖掘?学习链接:转录组标准分析后的数据挖掘、转录组文献解读
5. 微生物16S/ITS/18S分析原理及结果解读、OTU网络图绘制、cytoscape与网络图绘制课程
6. 生物信息入门到精通必修基础课:linux系统使用、docker搭建生物信息分析环境、实验室linux生信分析平台搭建、linux命令处理生物大数据、perl入门到精通、perl语言高级、R语言画图、R语言快速入门与提高、python语言入门到精通
7. 医学相关数据挖掘课程,不用做实验也能发文章:TCGA-差异基因分析、GEO芯片数据挖掘、 GEO芯片数据不同平台标准化 、GSEA富集分析课程、TCGA临床数据生存分析、TCGA-转录因子分析、TCGA-ceRNA调控网络分析
8.其他,NCBI数据上传、二代fastq测序数据解读、
9,高级生物信息分析课程:重测序数据自主分析、二代测序转录组数据自主分析、微生物扩增子分析课程实操
10.全部课程可点击:组学大讲堂视频课程
- 发表于 2020-11-10 14:17
- 阅读 ( 9808 )
- 分类:宏基因组
