蛋白质定量—MaxQuant软件分析多样品定量
在 蛋白质定量—MaxQuant软件的使用 这篇文章中介绍了如何使用MaxQuant进行蛋白质定量。但是只适用于样品少(11个样品以内)的分析,但是如果样品特别多(比如有18个样品)时,标记是不够用的,这时候可以将样品分成3组分析,每组使用6标测序。然后再使用MaxQuant定量。MaxQuant定量方法如下:
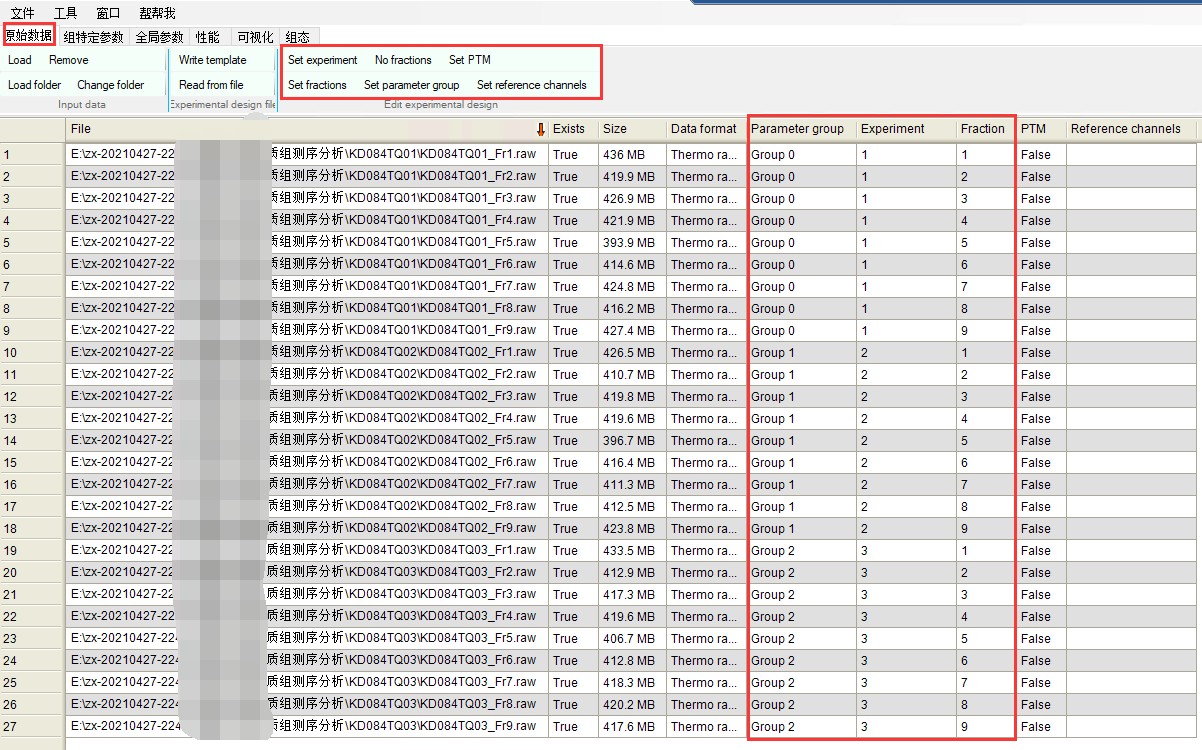
1.导入数据并分组
这里每组6个样品有9个原始数据文件,将每组对应的Parameter group 和 Experiment 设为一组,Fraction 设为1-9。如下图所示:
2.设置每组所使用的标记
在“组特定参数” 这里设置每组使用的标记,Group0、Group1、Group2三组都使用的6plex TMT。
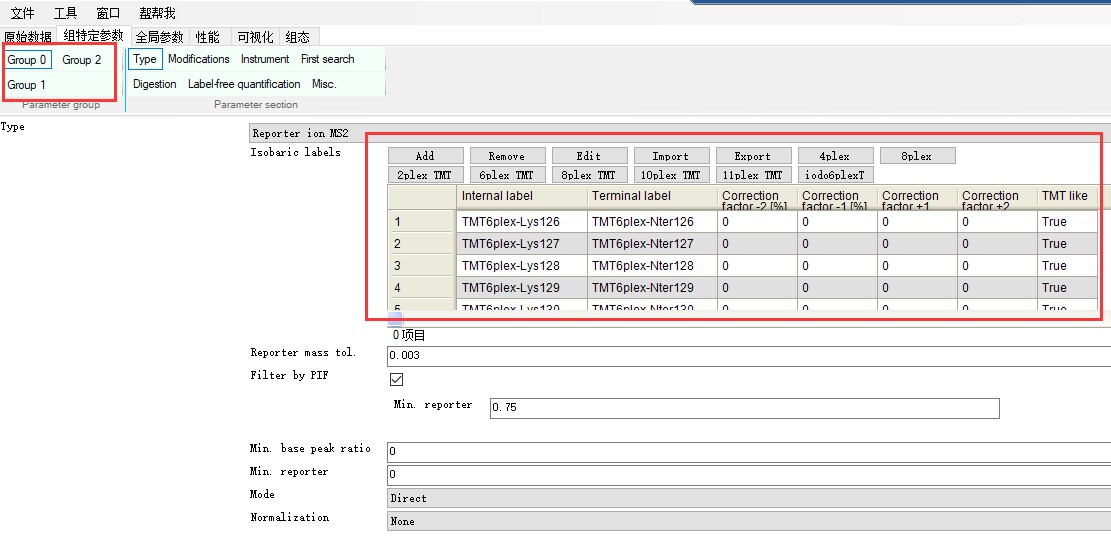
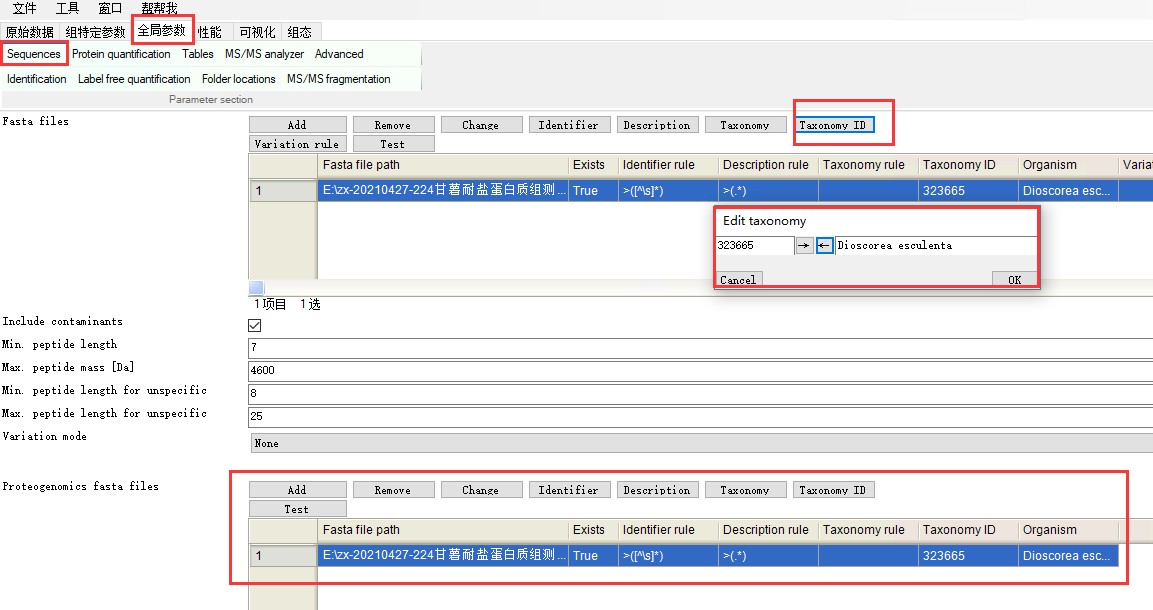
3.设置全局参数
Sequences 中添加物种蛋白质序列文件。并设置Taxonomy ID,输入物种拉丁文名称即可得到。
4.点击开始,启动运行。
5.将定量结果跑蛋白质流程。(可忽略)
跑流程是需要提供2个文件,第一个是sample_label.txt,如下所示:

第一列为样品id,第2列为样品使用的标记。
第二个文件为sample_info.txt,如下图所示:
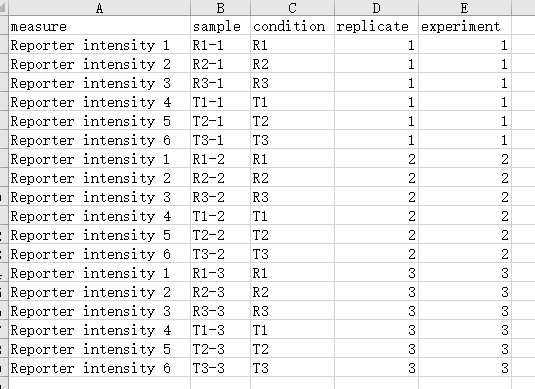 该文件为3组样品的信息,每6行为一组。
该文件为3组样品的信息,每6行为一组。
第一列由Reporter intensity 1开始,逐行累加,直到该组结束,下组重新由1开始。
第二列为样品名称,样品名称顺序与所使用标签顺序保持一致。
第三列为样品所属生物学重复分组。
第四列为生物学重复。
第五列为所属分组,与 1 中Experiment保持一致。
好了今天先介绍到这里,你也动手去试试吧!
此外,我们在网易云课堂上有各种教学视频,有兴趣可以了解一下:
1. 文章越来越难发?是你没发现新思路,基因家族分析发2-4分文章简单快速,学习链接:基因家族分析实操课程
2. 转录组数据理解不深入?图表看不懂?点击链接学习深入解读数据结果文件,学习链接:转录组(有参)结果解读;转录组(无参)结果解读
3. 转录组数据深入挖掘技能-WGCNA,提升你的文章档次,学习链接:WGCNA-加权基因共表达网络分析
4. 转录组数据怎么挖掘?学习链接:转录组标准分析后的数据挖掘
6. 更多学习内容:linux、perl、R语言画图,更多免费课程请点击以下链接:
- 发表于 2021-08-04 15:03
- 阅读 ( 6360 )
- 分类:蛋白质组学
