挖掘公共基因大数据的时代已经到来
经过NGS十余载的商业运营,要想找个生物实验室完全没听说过测序的也是很难了,为了各种实验目的,自己去测点数据已经是稀松平常的事情了。但是马上要到来的公共数据挖掘时代,您是否有足够的认识?
如果您还没有感知到的话,那让我来引导您回顾一下基因研究的不同时代及其特点,文章的最后我们也提供了如何修炼自身以紧跟趋势的途径。
单基因时代
20多年前,人类研究基因,主要是研究单个基因,定位一个性状关联的基因,克隆一个基因,定量一个基因的表达情况,当然现在仍有很多实验室的日常工作还是做这个,但是基因研究的主力手段已经另有其他了。
全基因组时代
人类基因组完成之后,芯片技术也得到了迅猛的发展,各种芯片出现,比如SNP芯片,CNV芯片,基因表达芯片,这使得我们能在单次实验中对全基因组的基因进行研究。如GWAS关联研究,不同组织基因表达差异研究。目前很多的实验室也已经采用这方面的研究技术。
大数据时代
10年前,随着NGS测序技术的发展,测序仪的通量越来越大,测序价格也越来越便宜,各种组学数据大规模产生。基因组,转录组,表观遗传等,这让我们可以从基因的不同层面来进行大数据的研究。据统计,目前SRA收录的高通量测序数据已经达到了18P,其增长趋势见下图。
在这个阶段大部分科研工作者一般对自有的实验材料进行数据收集,在分析层面一般仅关注某几个具体的角度,并没有全面的发掘数据的潜力。
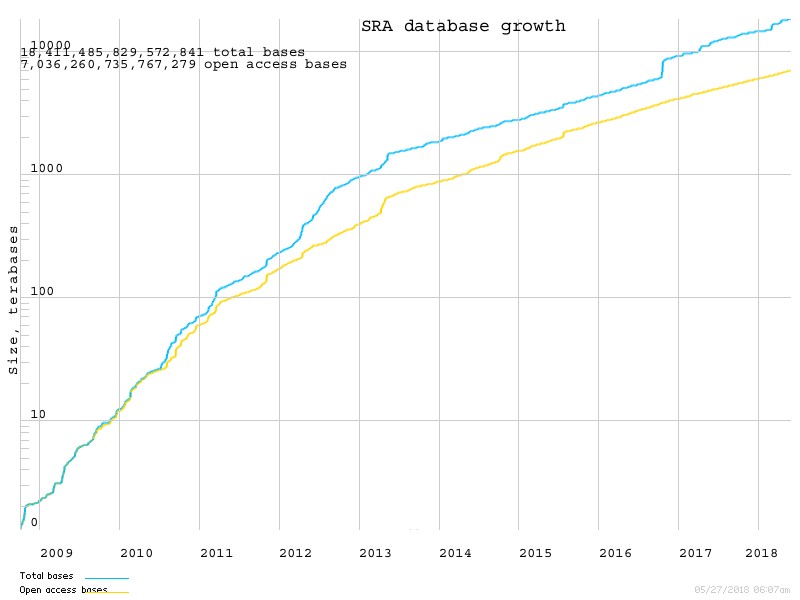
大数据挖掘时代
随着大量的数据产生,大规模样本,多组学的复杂数据在公共数据上堆积如山,但绝大部分的数据并没有得到充分的使用,部分嗅觉灵敏的科研工作者已经在利用各种分析技术对公共数据进行分析、利用并发表相关成果。
可以预见到,在下一个阶段,对公开数据的分析和利用必将受到广泛的关注。其中基因大数据的挖掘典范,当属TCGA数据库。
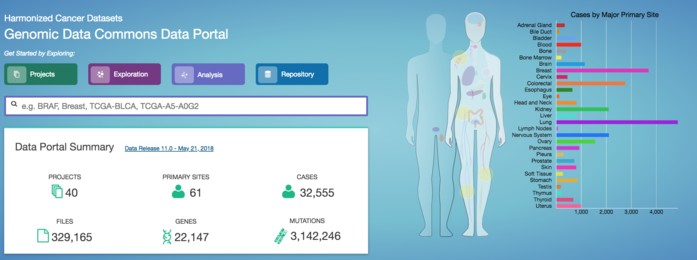
TCGA一A座金矿
TCGA(The Cancer Genome Atlas )数据库,目前收录了33种癌症,11000多列病人的多个组学的数据以及临床表型信息。组学数据包括基因组的变异,转录组,miRNA, 甲基化,蛋白质组等。到目前为止,依靠这座数据金矿,已经发表的SCI论文就有4140篇,其中不乏大量CNS级别的论文。这座金矿还没有完,将会持续被人挖掘。
趋势无法改变,我们只能紧跟
基因大数据挖掘的趋势无法改变,那我们只能紧随时代的步伐,加强自己的数据分析技能。
“组学大讲堂”一直致力于生物信息领域的教学,目前已经开设了多门针对公共数据挖掘的视频课程,比如“基因家族分析”,“共表达网络WGCNA分析”等,所有的课程可以打开下面的“阅读原文”进行查看。近期也将推出一门针对TCGA数据库进行数据挖掘的课程,敬请关注!
- 发表于 2018-06-01 11:25
- 阅读 ( 2702 )
- 分类:TCGA
