R语言用tidyr包进行长宽数据转换
长型和宽型数据在数据分析中非常常见。
一般人们看到的以行为样本以列为变量的数据为宽型数据,非常适合我们查看和理解,例如下图:
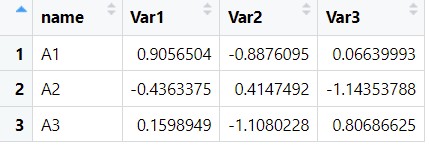
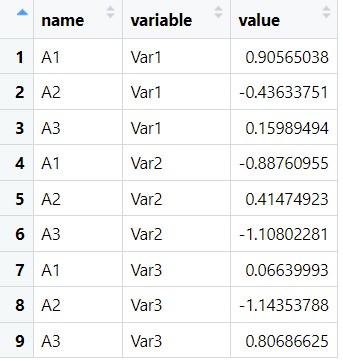
之前我们进行长宽数据转换使用较多的包是reshape或reshape2,而tidyr包可以看作是reshape2包的进化版本,
该包的作者依旧是Rstudio的首席科学家,R语言界的大神Hadley Wickham。
tidyr包往往与dplyr包结合使用,目前渐有取代reshape2包之势, 是值得关注的一个R包。接下来我们用例子学习一下如何使用tidyr包进行长宽数据转换。
widedata <- data.frame(ID=c(1,1,2,2),
Time=c(1,2,1,2),
x1=c(3,4,5,6),
x2=c(7,8,9,10))
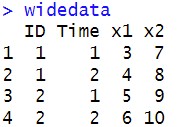
一、宽型数据转长型数据(Wide to long)
tidyr中的gather函数,跟reshape和reshape2中的melt函数的参数有较大的改变,但是更容易理解,用法为:
gather(data, key = "key", value = "value", ..., na.rm = FALSE, convert = FALSE, factor_key = FALSE)
其中的key和value是指定新生成的变量的变量名,...表示可以要进行转换的变量。
library(tidyr)
longdata <- gather(widedata, key = "variable", value ="value", x1:x2) # "variable" 和 "value" 是新生成的变量名,数据是根据 x1:x2 列生成的
 这里variable和value是自己命名的,不同于reshape包中melt函数自动生成的,相对更易于理解。
这里variable和value是自己命名的,不同于reshape包中melt函数自动生成的,相对更易于理解。
二、长型数据转宽型数据(Long to wide)
tidyr包中的spread函数,跟reshape包中的cast函数类似,不过参数与gather相对应,用法为:
spread(data, key, value, fill = NA, convert = FALSE, drop = TRUE, sep = NULL)
关键的参数是key和value,指定后就可以根据相应的key和value进行长到宽的转换
示例:
widedata2 <- spread(longdata, key = "variable", value = "value") #指定参数key和value对应的是longdata中的哪一列

三、另一个例子
可能上边的数据列数太多,有的小白不太好理解,这里用开头的数据再操作一遍,帮助大家理解。
很多情况下,我们用R进行一些数据处理后会得到长型数据如下:
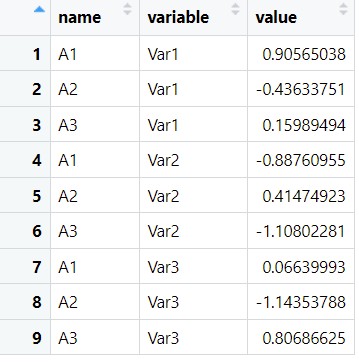 这种长型数据不太方便阅读,那我们来转换成方便阅读的宽型数据
这种长型数据不太方便阅读,那我们来转换成方便阅读的宽型数据
1.长型数据转宽型数据
widedf <- spread(longdata, key = "variable", value = "value")

那我们再把它转回到长型数据
2.宽型数据转长型数据
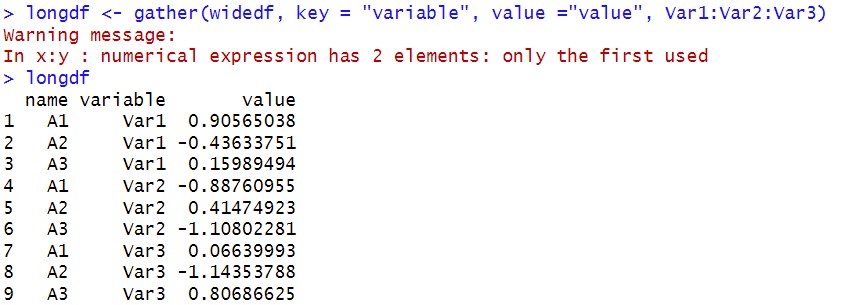
longdf <- gather(widedf, key = "variable", value ="value", Var1:Var2:Var3)
warning信息不用管
- 发表于 2023-03-15 18:06
- 阅读 ( 4218 )
- 分类:R
