典型相关性分析CCA与冗余分析RDA
1.典型相关(CCA)的基本原理canonical correspondence analysis 典型相关分析是研究两组变量之间关系的一种多变量统计分析方法,它可以反映两组变量之间的相互依赖的线性关系。设两组变量用x1...
1.典型相关(CCA)的基本原理canonical correspondence analysis
典型相关分析是研究两组变量之间关系的一种多变量统计分析方法,它可以反映两组变量之间的相互依赖的线性关系。设两组变量用x1,x2…xp,及y1,y2….yq表示,采用类似主成分分析的做法,在每一组变量中选择若干个具有代表性的综合指标(变量的线性组合),通过研究两组的综合指标间的关系来反映两组变量之间的相关关系。基本原理是:首先在每组变量中找出变量的线性组合,使其具有最大相关性,如此继续下去,直到两组变量之间的相关性被提取完毕。
在单变量复相关中,有p个x变量和一个y变量,分析的目的在于找出适当的回归系数作为这P个x变量的加权值,使p个x变量线性组合分数与这一个y变量分数之间的相关最大。在典型相关分析中也有p个x变量,但是y变量却有q个(q>1)。典型相关的目的在于找出这p个x变量的加权值和这q个y变量的加权值,使这p个x变量线性组合分数与这q个y变量线性组合分数相关程度达到最大。————王斌会著《多元统计分析与R语言建模》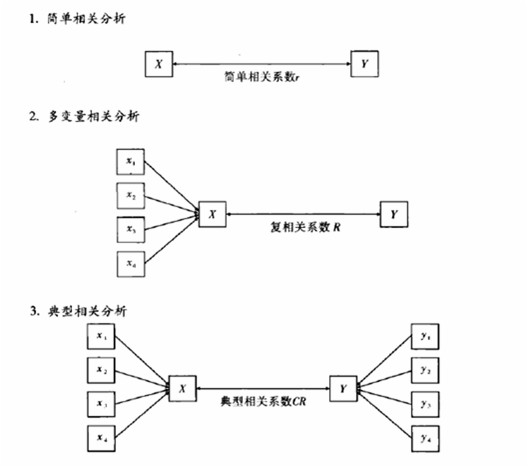
2.冗余分析(RDA)redundancy analysis
RDA是一种结合回归和主成分分析(PCA)的方法。它是多元回归分析的直接扩展,用于多变量响应数据建模。 RDA是生态学家手中极其强大的工具。
先用species-sample数据(97%相似性的样品OTU表)做DCA(detrended correspondence analysis) 分析,看分析结果中Lengths of gradient 的第一轴的大小。如果大于4.0,就应该选CCA;如果3.0-4.0 之间,选RDA 和CCA均可;如果小于3.0,RDA 的结果要好于CCA。
目前CCA要比RDA用得更普遍,有两个原因:
- 大部分情况下,两者的分析结果并差别并不大。其实,CCA非线性模型其实可以容纳线性模型,线性关系可以算是非线性模型的特例。所有用RDA可以做的,CCA也可以做,只不过在如果梯度比较短的话RDA要精确一点。但是,如果是非线性关系,用线性的RDA来分析,那个准确度就大大打折扣了。因为,本来点就不在同一条直线上,现在非得用直线去拟合,肯定不合适。这也是为什么SD小于3也可以用CCA,但是SD大于4,就不能用RDA的原因。
- 正因为大家都用CCA,用得多了,文献多了,大家为了方便比较,所有更多的选择是CCA,RDA自然就越来越少了。
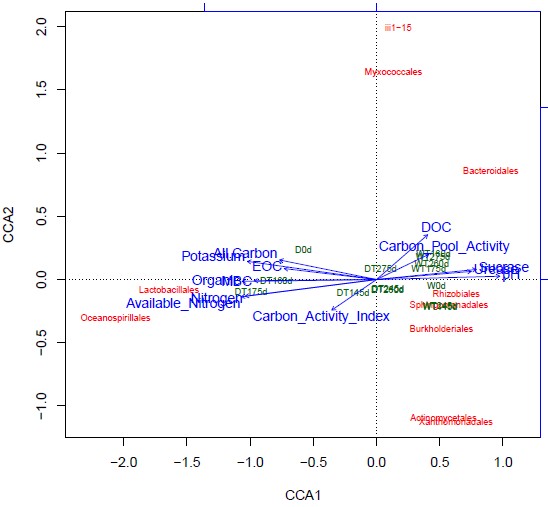
上图的CCA分析结果图,图中箭头代表不同的环境因子,红色的代表不同的微生物,绿色的代表不同的样本(当然这个图可以只展示样本和和环境因子2种)。
环境因子的箭头的长度代表相应的环境因子与研究对象(样品,微生物)相关程度的大小,越长代表其对所研究对象(样品,微生物)的分布影响越大。箭头连线之间的夹角的代表其相关性,为锐角是说明2个环境因子之间是正相关,钝角是负相关。
- 发表于 2023-05-09 17:37
- 阅读 ( 13774 )
- 分类:基础知识
