Linux三剑客之grep-文件中的信息捕获
在Linux系统中,grep(Global Regular Expression Print)是一个用于在文本文件中搜索字符串或正则表达式的命令行工具。它可以有效地查找包含特定模式的行,并将其打印出来。今天,我们结合以下...
在Linux系统中,grep(Global Regular Expression Print)是一个用于在文本文件中搜索字符串或正则表达式的命令行工具。它可以有效地查找包含特定模式的行,并将其打印出来。今天,我们结合以下示例,深入了解一下grep命令的详细使用方法。
grep是什么
grep命令,全称为Global Regular Expression Print,它逐行读取输入文件,根据指定的字符在每一行中进行搜索,然后将结果输出。grep还支持正则表达式进行复杂的信息捕获。
基本语法
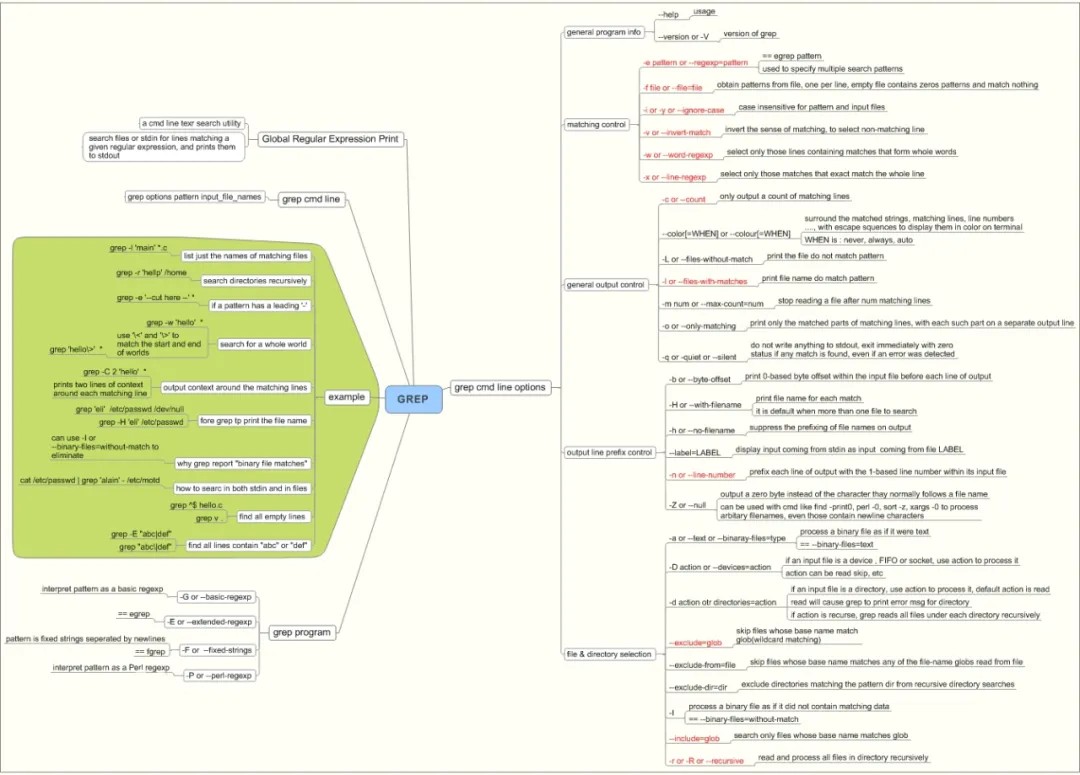
grep [选项] PATTERN [FILE...]
# PATTERN:要搜索的字符串或正则表达式。
# FILE:要搜索的文件名,多个文件用空格分隔。
其中每个[选项]所代表的意思如下:
正则表达式选择与解析:
-E, --extended-regexp PATTERN 是一个扩展正则表达式(ERE)
-F, --fixed-strings PATTERN 是一系列用换行符分隔的固定字符串
-G, --basic-regexp PATTERN 是一个基本正则表达式(BRE)
-P, --perl-regexp PATTERN 是一个Perl正则表达式
-e, --regexp=PATTERN 使用PATTERN进行匹配
-f, --file=FILE 从FILE中获取PATTERN
-i, --ignore-case 忽略大小写差异
-w, --word-regexp 强制PATTERN仅匹配完整的单词
-x, --line-regexp 强制PATTERN仅匹配完整的行
-z, --null-data 数据行以0字节结束,而不是换行符
其他选项:
-s, --no-messages :不显示错误消息
-v, --invert-match :选择非匹配的行
-V, --version :显示版本信息并退出
--help :显示此帮助文本并退出
输出控制:
-m, --max-count=NUM 匹配NUM次后停止
-b, --byte-offset 输出每行时打印字节偏移量
-n, --line-number 输出每行时打印行号
--line-buffered 每行输出时刷新输出
-H, --with-filename 为每条匹配结果打印文件名
-h, --no-filename 输出时不显示文件名前缀
--label=LABEL 使用LABEL作为标准输入文件名前缀
-o, --only-matching 只显示与模式匹配的文件部分
-q, --quiet, --silent 关闭所有常规输出
--binary-files=TYPE 假设二进制文件为TYPE; TYPE为'binary'、'text'或'without-match'
-a, --text 相当于--binary-files=text
-I 相当于--binary-files=without-match
-d, --directories=ACTION 处理目录的方式;ACTION为'read'、'recurse'或'skip'
-D, --devices=ACTION 处理设备、FIFO和套接字的方式;ACTION为'read'或'skip'
-r, --recursive 相当于--directories=recurse
-R, --dereference-recursive 同样,但跟踪所有符号链接
--include=FILE_PATTERN 仅搜索匹配FILE_PATTERN的文件
--exclude=FILE_PATTERN跳过匹配 FILE\_PATTERN 的文件和目录。
--exclude-from=FILE 跳过任何文件模式匹配的文件。
--exclude-dir=PATTERN 匹配 PATTERN 的目录将被跳过。
-L, --files-without-match 仅打印包含匹配项的 FILE 的名称。
-l, --files-with-matches 仅打印包含匹配项的 FILE 的名称。
-c, --count 仅打印每个 FILE 中匹配行的计数。
-T, --initial-tab 使制表符对齐(如果需要的话)。
-Z, --null 打印 FILE 名称后面的 0 字节。
上下文控制:
-B, --before-context=NUM 打印NUM行的前置上下文
-A, --after-context=NUM 打印NUM行的后置上下文
-C, --context=NUM 打印NUM行的输出上下文
-NUM 与--context=NUM相同
--group-separator=SEP 使用SEP作为分组符
--no-group-separator 使用空字符串作为分组符
--color[=WHEN],
--colour[=WHEN] 使用标记来突出匹配的字符串;WHEN是'always'、'never'或'auto'
我们还可以通过man grep来查看grep的使用说明
命令使用
1.基本搜索:
查找文件 example.txt 中包含字符串 "hello" 的行
grep "hello" example.txt
2.忽略大小写:
在文件 example.txt 中查找 "hello",忽略大小写
grep -i "hello" example.txt
3.显示行号:
查找字符串 "error",并显示匹配行的行号
grep -n "error" example.txt
4.反向匹配:
查找文件中不包含字符串 "foo" 的行
grep -v "foo" example.txt
5.递归搜索:
在当前目录及其子目录中查找 "main"在当前目录及其子目录中查找 "main"
grep -r "main"
6.统计匹配行数
统计文件 example.txt 中包含 "test" 的行数
grep -c "test" example.txt
7.只输出匹配的部分
从文件中提取匹配字符串
grep -o "pattern" file.txt
8.显示上下文行
显示匹配行以及其前后各两行
grep -C 2 "hello" example.txt
9.使用正则表达式
查找以 "start" 开头的行:
grep "^start" example.txt
查找以 "end" 结尾的行:
grep "end$" example.txt
查找有 "start" 或者 "end" 的行:
grep -E "start|end" example.txt
grep "start\|end" example.txt #如果不加-E就要用转义符
参考资料
https://www.runoob.com/linux/linux-comm-grep.html
https://blog.csdn.net/modaner/article/details/142817283
- 发表于 2024-11-12 17:36
- 阅读 ( 1828 )
- 分类:linux
