误差线该用标准差还是标准误?
误差线对应的表示的到底是标准差还是标准误?其实……都可以,此外还可以用特定的置信区间(譬如,95%的区间)
误差线 主要指示数据每一个数据点的误差(或不确定性)范围,显示潜在的误差或相对于系列中每一数据标志的不确定程度,以更准确的方式呈现数据【参考1】
Wikipedia 也对误差线(error bar,也称误差条、误差棒) 进行了说明,可以用标准差(standard deviation SD)、标准误(或称标准误差,standard error,SE)以及置信区间表示。所以在论文中明确写明你用的是哪一种即可。
标准差
标准差,是离均差平方的算术平均数的平方根,用σ表示,(总体)标准差计算公式:
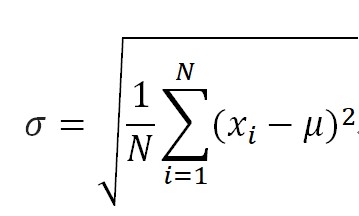
公式中数值X1,X2,X3,......XN(皆为实数),其平均值(算术平均值)为μ,标准差为σ。
注意:在部分公式中,根号内常除以自由度(N-1)而非N,主要是因为:
如是总体(即总体标准差),根号内除以N(对应excel函数:STDEVP),多用σ表示;
如是抽样(即样本标准差),根号内除以(N-1)(对应excel函数:STDEV),多用s表示;
因为我们大量接触的是样本,所以普遍使用根号内除以(N-1),故,在抽样统计样本标准差,计算公式是:
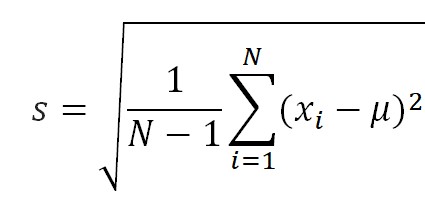
实际情况下,往往因总体标准差未知,常用样本标准差来估计总体标准差。由此,误差线的范围可以表示为一下两种:
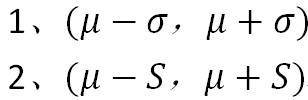
标准误
标准误计算公式
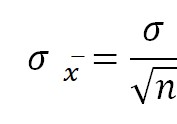
σ表示总体标准差,n为样本数。当总体标准差未知是,利用样本标准差进行估计:
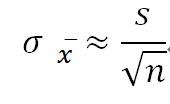
(具体可参考 标准误 维基百科解释)
而误差线的范围也就可以表示为:
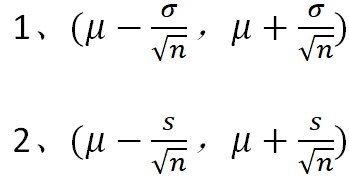
置信区间
它指样本统计量所构造的总体参数的估计区间,涉及了区间估计(点估计)。而置信区间 的计算需要根据σ是否已知以及样本量的不同分别进行估计。
1、
σ(总体标准差)已知或未知但为大样本(一般样本量大于等于30),认为样本平均数近似服从正态分布:
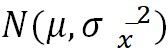 从而进行区间估计获得:
从而进行区间估计获得:
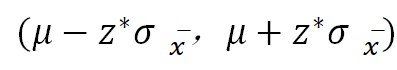 σ(总体标准差)已知可以直接计算标准误,未知则先由样本标准差s估计总体标准差再进行计算:
σ(总体标准差)已知可以直接计算标准误,未知则先由样本标准差s估计总体标准差再进行计算:

z*可以通过正态分布检验查表获得,不同的置信度数值不同,常见置信度(C)数据如下(双侧):
| C | z* |
| 99% | 2.576 |
| 98% | 2.326 |
| 95% | 1.96 |
| 90% | 1.645 |
譬如常见的0.95置信区间 是1.96倍的标准误(误差线的范围也就如下):
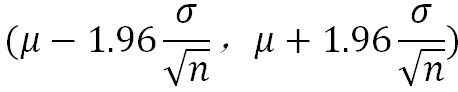
2、
σ(总体标准差)未知,且为小样本(一般样本量小于30,很多生物研究类实验样本量往往少于30且σ未知),则选择t-分布: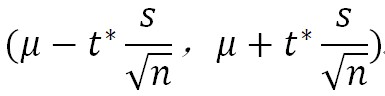 t*也是通过t-检验查表获得,其数值与置信度以及自由度(n-1)有关(此处适用于双侧):
t*也是通过t-检验查表获得,其数值与置信度以及自由度(n-1)有关(此处适用于双侧):
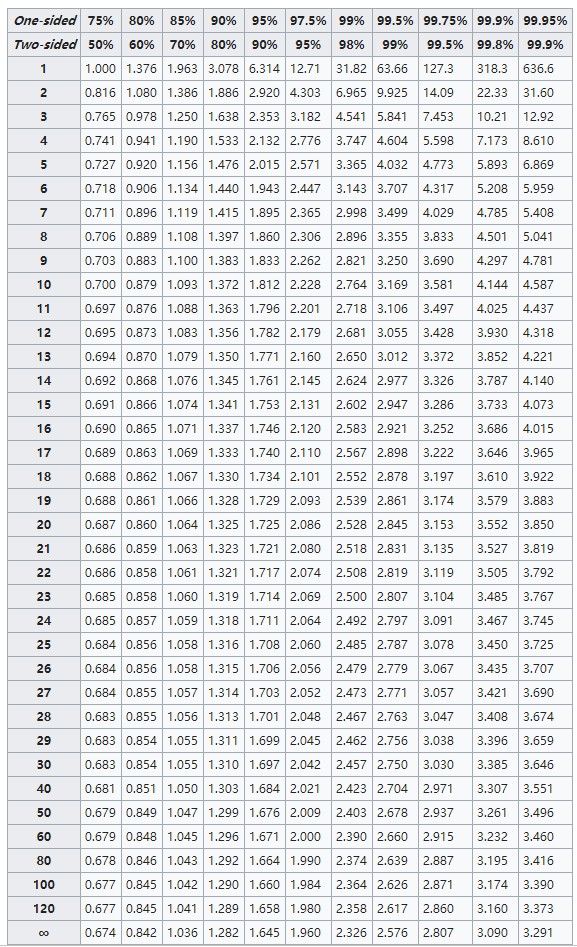
举个栗子来说,一般设置三个生物学重复测量数据n=3(自由度为2),0.95置信区间对应 t*是4.303,也就是4.303倍的标准误(误差线范围):
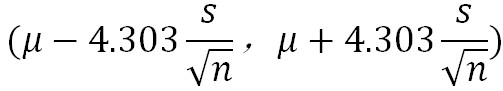
参考:
1 王海科 科技论文中平均差、标准差、标准误和误差线的正确使用
2 李春喜、邵云、姜丽娜 生物统计学(第四版)科学出版社出版
如果想提升自己的绘图技能,我们推荐:Cytoscape与网络图绘制课程、R语言绘图基础(ggplot2)
更多生物信息课程:
1. 文章越来越难发?是你没发现新思路,基因家族分析发2-4分文章简单快速,学习链接:基因家族分析实操课程、基因家族文献思路解读
2. 转录组数据理解不深入?图表看不懂?点击链接学习深入解读数据结果文件,学习链接:转录组(有参)结果解读;转录组(无参)结果解读
3. 转录组数据深入挖掘技能-WGCNA,提升你的文章档次,学习链接:WGCNA-加权基因共表达网络分析
4. 转录组数据怎么挖掘?学习链接:转录组标准分析后的数据挖掘、转录组文献解读
5. 微生物16S/ITS/18S分析原理及结果解读、OTU网络图绘制、cytoscape与网络图绘制课程
6. 生物信息入门到精通必修基础课:linux系统使用、perl入门到精通、perl语言高级、R语言入门、R语言画图
7. 医学相关数据挖掘课程,不用做实验也能发文章:TCGA-差异基因分析、GEO芯片数据挖掘、GEO芯片数据标准化、GSEA富集分析课程、TCGA临床数据生存分析、TCGA-转录因子分析、TCGA-ceRNA调控网络分析
8.其他,二代测序转录组数据自主分析、NCBI数据上传、二代测序数据解读
- 发表于 2018-09-30 14:58
- 阅读 ( 42292 )
- 分类:科研作图
