一大波三代文章正在来袭!有没有你滴?
Iso-Seq 即是 isoform sequencing, 翻译成中文是同源异构体测序,大家都知道真核生物基因在转录过程中是会发生可变剪接的,即一个基因会产生多种transcript isoforms,生物就是通过这种方式来增加基编码因蛋白的潜能。来源于同一个基因的不同transcript isoforms结构有很大的差异,在功能上有时甚至会产生相反的效应。之前的很多年,我们一直以来很熟悉、常在用的二代测序技术,也是就常说的RNA-seq。其技术特点是转录组本需经打断再拼接,短的RNA-seq 不能跨越全长的转录本,也就不能精准的描绘出不同的transcript isoforms。这样看来,我们以前追过的的RNA-seq其实都是有巨大缺陷的,甚至是错误的。
第三代单分子全长转录组测序技术可以直接得到全长转录本,无需组装。能更好地改善基因表达定量结果,发现新的基因和转录异构体,鉴定可变剪切及基因融合现象。随着三代测序技术不断完善,通量越来越高,价格越来越低,近年来热度也越来越高,目测即将有一大波三代文章袭来,是不是也有您的呢?没有的话抓紧行动吧! 下面以一篇研究丹参不同组织部位丹参酮生物合成的文章来介绍三代全长测序技术在转录组研究中的应用。
丹参酮一般认为产生于丹参根部周皮部,所以本文分别取了根部的周皮(periderm)、韧皮(phloem)、木质(xylem)3种类型的根部组织,每种类型组织设置3个生物学重复,总共9个样本。9个样本单独建二代转录组文库做基因差异表达分析;另外,作者还将9个样本等量混匀,进行三代全长转录组测序。
一般认为丹参酮产生于丹参根部的周皮部,作者先通过化学染色的方法对丹参酮合成部分进行定位,发现丹参酮主要集中于周皮部,如下图。该部分数据对于体现文章逻辑性很有帮助,值得大家学习借鉴。

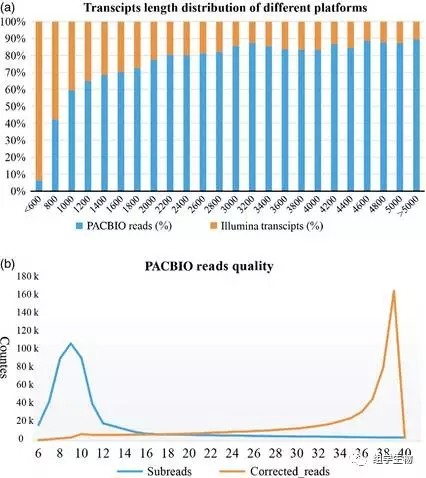
接下来作者通过三代全长转录组及二代转录组对3组织基因表达情况进行了分析,由于三代数据准确性稍差,作者先通过与丹参基因组比对评估测序数据的准确性,用二代数据对三代数据进行了校正,最终共得到高质量的去冗余 isoform 16241条。
结合二代数据分析了与丹参酮及其前体合成相关的基因的表达情况,发现了在根部周皮部特异表达及高表达丹参酮合成相关基因,SmCPS1、SmKSL1、GGPS、IPI、CYP等;
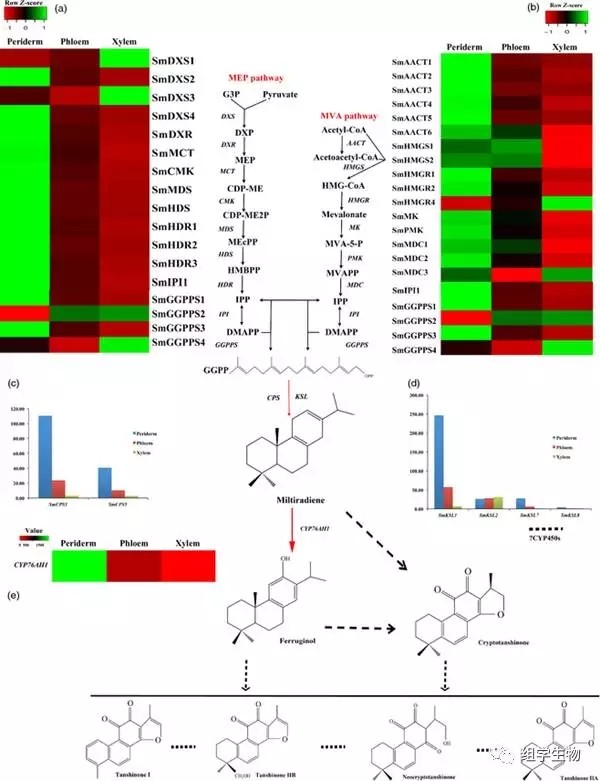
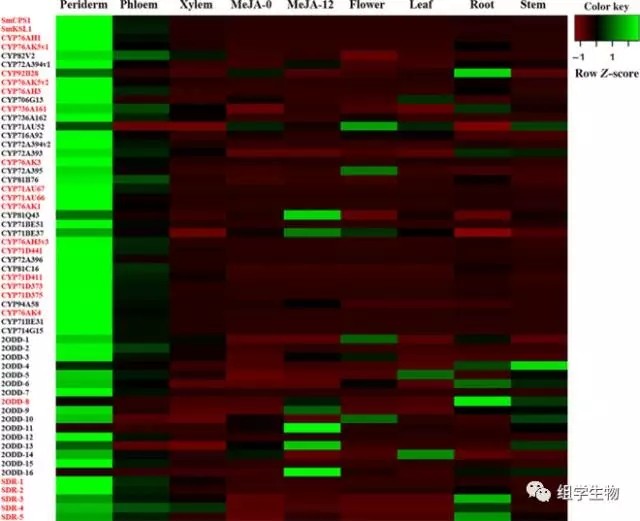
结合以上结果,作者推断丹参酮合成完全在根周皮部进行,并通过qPCR对 CYP基因家族中FPKM >10的96个及33在周皮中33个特异表达的cyp基因在丹参根、茎、叶、花及经茉莉酸甲酯处理后的叶中进行验证,最终鉴定得到包括CYP76AH1在内的16个特异性表达最明显的cyp基因,以待进行后续深入研究。基因共表达网络分析发现 2ODD-8和5个 SDRs家族基因在周皮中也是特异性表达,说明这些基因也可能参与丹参酮的合成。
isoform detection and prediction (IDP)分析共得到16241条isoform,其中包括10 323 multi-exon基因, 在这10323个multi-exon基因中有4165 (40%)发生了可变剪接,其中多于15%的发生了多于2种的可变剪接方式。所有可变剪接事件中, 内含子保留占21% ,外显子跳跃占 4% ,5'区发生可变剪接的基因占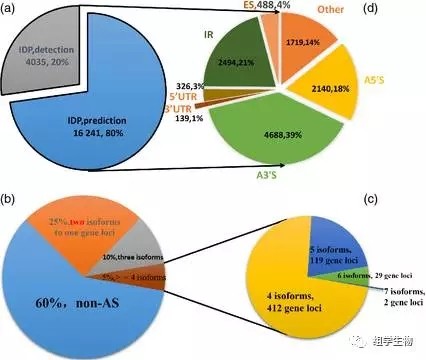
18% ,3'区占 39%。分析这些isoform发现,isoprenoid/terpenoid 等途径上某些酶发生的可变剪接事件可能调控着丹参酮、异戊二烯及萜类化合物的合成,值得进一步试验去验证。
1. 转录组数据理解不深入?图表看不懂?点击链接学习深入解读数据结果文件,学习链接:转录组(有参)结果解读;转录组(无参)结果解读
2. 转录组数据深入挖掘技能-WGCNA,提升你的文章档次,学习链接:WGCNA-加权基因共表达网络分析
3. 转录组数据怎么挖掘?学习链接:转录组标准分析后的数据挖掘
5. 更多学习内容:linux、perl、R语言画图,更多免费课程请扫描下方二维码:

- 发表于 2018-04-22 12:23
- 阅读 ( 4124 )
- 分类:转录组
