GEO数据挖掘生物信息文章解读(拟南芥重金属)
前面我们介绍了GEO数据挖掘的文章(更多见文末链接),大多数都为人类癌症相关的数据挖掘,其实GEO数据库中也有很多动植物相关的数据,也可以用于数据挖掘然后发表SCI论文,这里给大家介绍一篇利用GEO数据库当中的公开数据,挖掘拟南芥中与重金属响应相关基因的文章。
2019年发表在PeerJ杂志上,IF=2.353,虽然分数不高但是非常有借鉴意义。

1.数据来源
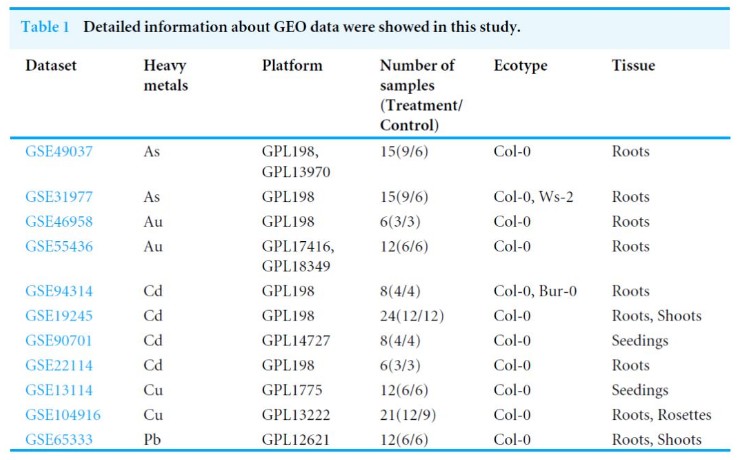
作者在GEO数据库当中找到了11组和重金属(As, Au, Cd, Pb and Cu)相关的基因芯片表达数据用于查找拟南芥当中与重金属响应相关的关键基因。
2.关键差异基因筛选分析
分别对这11组数据用limma包做差异表达分析,筛选条件为:corrected P-value < 0.05 and |log2FC| > 1。11组数据筛选了很多差异基因,这里就不再赘述分别是多少了。

查找共同的关键基因:作者用了一个RRA的分析方法用于查找11组数据中差异基因中关键的基因。该方法简单介绍:每个基因在每个实验中按照表达量进行秩次排序,如果不是关键基因理论上应该是随机排序,但是,如果一个基因在所有实验中排名都很高,则该基因差异表达的与重金属相关的可能性越大。根据这个筛选方法,作者共筛选到168 DEGs comprising 109 down-regulated and 59 up-regulated。其中差异表达最大的上调top20基因:AT3G46270, ATCSLB05, AT3G19030, COL9, BCAT4, ELF4,CYP83A1, AT1G76800, AT1G61740, CLE6, AT4G01440, AT1G72200, MOT1, AT5G52790,AT4G40070, AT4G25250, EXGE-A1, NR1, AT5G19970 and CYP735A2;下调top20基因:DIN2, WRKY75,AT4G15120, CYP81F2, AT1G73480, AT1G72900, PGPS1, AT5G06730, AT1G35910,CYP81D8, AT3G12320, ATERF6, AT1G12200, AT5G25450, AT4G28460, NILR1, HSP70,APRR9, Fes1A and AT3G02800。这些基因在不同数据中的表达热图如下:

3.差异基因GO和KEGG富集分析
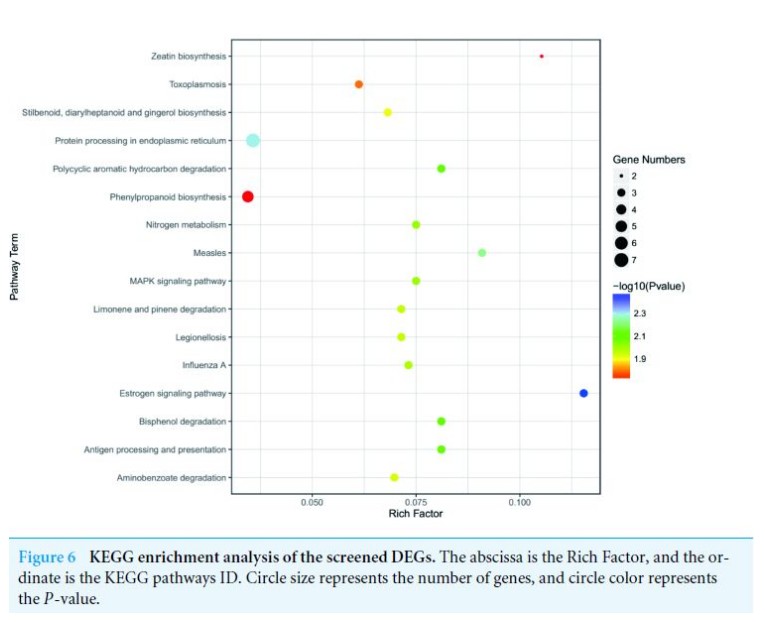
利用GOATOOLS对差异基因进行GO富集分析发现:这些基因在生理过程(GO:0008150),细胞生理过程(GO:0009987),对刺激的生理响应(GO:0050896),对生物/非生物胁迫的响应(GO:0006950)有明显的富集;

再利用KOBAS进行代谢通路富集发现差异基因在 雌激素信号通路,玉米素生物合成,麻疹,抗原加工和呈递,MAPK信号通路和氮代谢等代谢中富集。
4.蛋白互作网络分析
利用STRING蛋白互作网络数据库,构建差异基因的蛋白互作网络分析,再用cytoscape软件分析互作网络共找到9个关键hub基因。

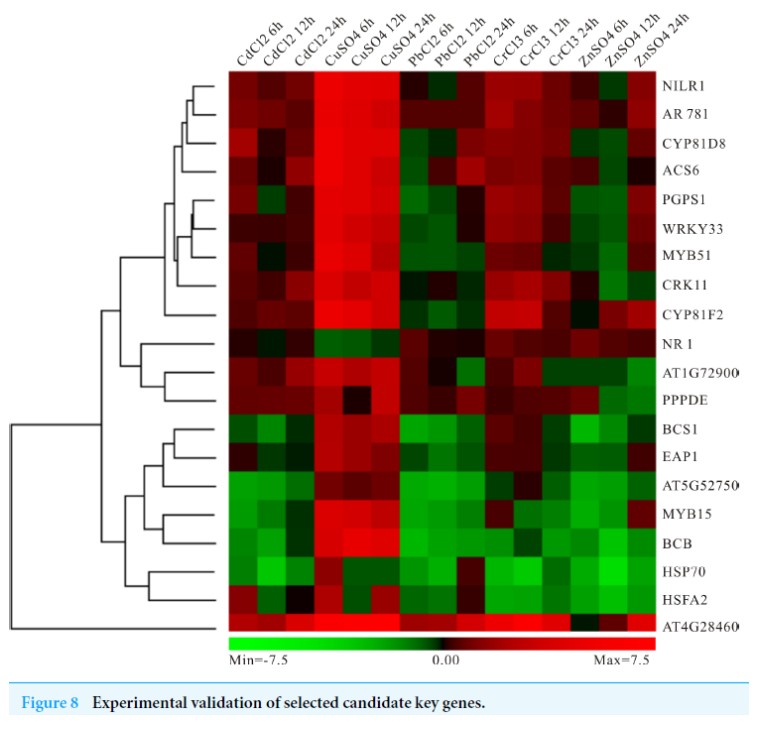
5.RT-qPCR验证关键基因的表达情况
挑选了20个关键基因进行实时定量表达验证,不同的基因在重金属处理后表达模式不尽相同:
6.总结
作者通过对11组GEO数据进行差异分析初步筛选,得到很多差异分析结果。不像以前的文章直接绘制维恩图取交集得到关键的差异分析结果,本文作者通过RRA秩次检验分析筛选关键的差异基因,方法新值得借鉴。另外,生信类文章投入产出比很高,作者只是做了定量PCR会有经费投入,其他都是生信分析不用投入任何经费。
参考文献:https://peerj.com/articles/6495/
推荐课程:GEO芯片数据挖掘、 GEO芯片数据不同平台标准化
以上课程需要有R语言基础,建议提前学习:R语言快速入门与提高、R语言画图
更多生物信息课程:
1. 文章越来越难发?是你没发现新思路,基因家族分析发2-4分文章简单快速,学习链接:基因家族分析实操课程、基因家族文献思路解读
2. 转录组数据理解不深入?图表看不懂?点击链接学习深入解读数据结果文件,学习链接:转录组(有参)结果解读;转录组(无参)结果解读
3. 转录组数据深入挖掘技能-WGCNA,提升你的文章档次,学习链接:WGCNA-加权基因共表达网络分析
4. 转录组数据怎么挖掘?学习链接:转录组标准分析后的数据挖掘、转录组文献解读
5. 微生物16S/ITS/18S分析原理及结果解读、OTU网络图绘制、cytoscape与网络图绘制课程
6. 生物信息入门到精通必修基础课:linux系统使用、biolinux搭建生物信息分析环境、linux命令处理生物大数据、perl入门到精通、perl语言高级、R语言画图、R语言快速入门与提高
7. 医学相关数据挖掘课程,不用做实验也能发文章:TCGA-差异基因分析、GEO芯片数据挖掘、 GEO芯片数据不同平台标准化 、GSEA富集分析课程、TCGA临床数据生存分析、TCGA-转录因子分析、TCGA-ceRNA调控网络分析
8.其他,二代测序转录组数据自主分析、NCBI数据上传、二代fastq测序数据解读、
9.全部课程可点击:组学大讲堂视频课程
延申阅读
GEO芯片数据下载 |GEO数据与WGCNA--挖掘胶质瘤共表达网络的关键模块与通路|GEO和TCGA套路文章解说 | 基因芯片表达差异分析 | GSEA法基因功能富集分析原理详解! | 挖别人的数据,发自己的文章 | TCGA-数据挖掘 | 转录因子研究方法! |GEO芯片数据挖掘(直肠癌)|GEO数据挖掘(宫颈癌)
- 发表于 2019-08-11 11:01
- 阅读 ( 5003 )
- 分类:GEO
