关于基因家族课程中基因在染色体上位置提取不到问题分析
网易云基因家族课程中,在提取基因在染色体上的位置信息使用到的是一个脚本,大家经常的遇到一个问题就是没有提取出来信息。
下面是可能存在的问题之一:
脚本在处理信息时与gff文件的匹配如下所示:
脚本:
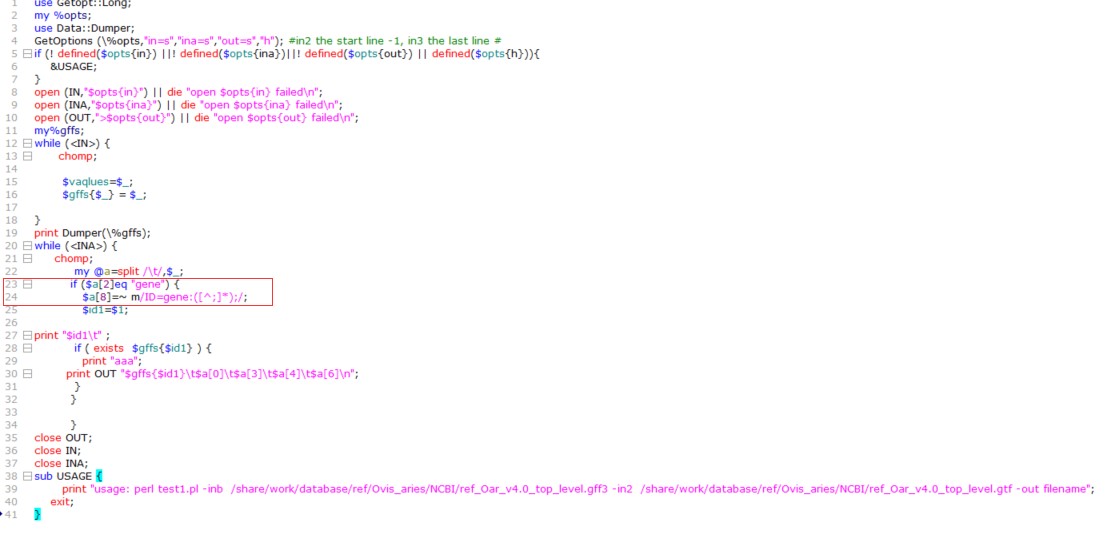 匹配第八列脚本如图红框所示。
匹配第八列脚本如图红框所示。
对应的gff文件是下面的格式:
1 araport11 gene 3631 5899 . + . ID=gene:AT1G01010;Name=NAC001;biotype=protein_coding
1 araport11 mRNA 3631 5899 . + . ID=transcript:AT1G01010.1;Parent=gene:AT1G01010
1 araport11 five_prime_UTR 3631 3759 . + . Parent=transcript:AT1G01010.1
1 araport11 exon 3631 3913 . + . Parent=transcript:AT1G01010.1;Name=AT1G01010.1.exon1;constitutive=1
1 araport11 CDS 3760 3913 . + 0 ID=CDS:AT1G01010.1;Parent=transcript:AT1G01010.1;protein_id=AT1G01010.1
1 araport11 exon 3996 4276 . + . Parent=transcript:AT1G01010.1;Name=AT1G01010.1.exon2;constitutive=1
1 araport11 CDS 3996 4276 . + 2 ID=CDS:AT1G01010.1;Parent=transcript:AT1G01010.1;protein_id=AT1G01010.1
1 araport11 exon 4486 4605 . + . Parent=transcript:AT1G01010.1;Name=AT1G01010.1.exon3;constitutive=1
1 araport11 gene 6788 9130 . - . ID=gene:AT1G01020;Name=ARV1;biotype=protein_coding
1 araport11 mRNA 6788 8737 . - . ID=transcript:AT1G01020.6;Parent=gene:AT1G01020;biotype=protein_coding
1 araport11 exon 6788 7069 . - . Parent=transcript:AT1G01020.6;Name=AT1G01020.2.exon8;constitutive=0
1 araport11 three_prime_UTR 6788 7069 . - . Parent=transcript:AT1G01020.6
1 araport11 three_prime_UTR 7157 7314 . - . Parent=transcript:AT1G01020.6
1 araport11 exon 7157 7450 . - . Parent=transcript:AT1G01020.6;Name=AT1G01020.2.exon7;constitutive=0
1 araport11 CDS 7315 7450 . - 1 ID=CDS:AT1G01020.6;Parent=transcript:AT1G01020.6;protein_id=AT1G01020.6
1 araport11 exon 7564 7649 . - . Parent=transcript:AT1G01020.6;Name=AT1G01020.1.exon6;constitutive=1
脚本在遇到gff文件第三列为gene时,匹配gene_id,但是不同的平台和软件gene_id对应的前缀也不一样,如上图所示前缀是ID=gene:,所以脚本匹配时是:
$a[8]=~ m/ID=gene:([^;]*);/;
如果你的gff文件第八列gene_id对应的前缀也不一样,例如如下所示:
1 araport11 gene 11649 13714 . - . ID=AT1G01030;Name=NGA3;biotype=protein_coding
你就需要修改一下脚本,将匹配内容改为如下所示:
$a[8]=~ m/ID=([^;]*);/;
这样脚本才能正确匹配,提取信息。
更多生物信息课程:
1. 文章越来越难发?是你没发现新思路,基因家族分析发2-4分文章简单快速,学习链接:基因家族分析实操课程、基因家族文献思路解读
2. 转录组数据理解不深入?图表看不懂?点击链接学习深入解读数据结果文件,学习链接:转录组(有参)结果解读;转录组(无参)结果解读
3. 转录组数据深入挖掘技能-WGCNA,提升你的文章档次,学习链接:WGCNA-加权基因共表达网络分析
4. 转录组数据怎么挖掘?学习链接:转录组标准分析后的数据挖掘、转录组文献解读
5. 微生物16S/ITS/18S分析原理及结果解读、OTU网络图绘制、cytoscape与网络图绘制课程
6. 生物信息入门到精通必修基础课,学习链接:linux系统使用、perl入门到精通、perl语言高级、R语言画图
7. 医学相关数据挖掘课程,不用做实验也能发文章,学习链接:TCGA-差异基因分析、GEO芯片数据挖掘、GSEA富集分析课程、TCGA临床数据生存分析、TCGA-转录因子分析、TCGA-ceRNA调控网络分析
8.其他课程链接:二代测序转录组数据自主分析、NCBI数据上传、二代测序数据解读。
- 发表于 2018-06-08 10:39
- 阅读 ( 6333 )
- 分类:基因家族分析
