sklearn中使用pipeline重复处理测试集
pipeline 实现了对全部步骤的流式化封装和管理,可以很方便地使参数集在新数据集上被重复使用。
可以用于下面几处:
模块化 Feature Transform
自动化 Grid Search
自动化 Ensemble Generat...
pipeline 实现了对全部步骤的流式化封装和管理,可以很方便地使参数集在新数据集上被重复使用。
可以用于下面几处:
模块化 Feature Transform
自动化 Grid Search
自动化 Ensemble Generation

import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import r2_score, mean_squared_error
# 产生训练数据
X_train = 6 * np.random.rand(100, 1) - 3
y_train = 0.5 * X_train ** 2 + X_train + 2 + np.random.rand(100, 1)
plt.scatter(X_train, y_train)
plt.show()
pf = PolynomialFeatures()
ss = StandardScaler()
ln = LinearRegression()
model = Pipeline(steps=(('多项式', pf), ('标准化', ss),('回归', ln)))
model.fit(X_train, y_train)
# 生成测试集
X_test = 6 * np.random.rand(100, 1) - 3
y_test = 0.5 * X_test ** 2 + X_test + 2 + np.random.rand(100, 1)
# 预测和评价
y_pred = model.predict(X_test)
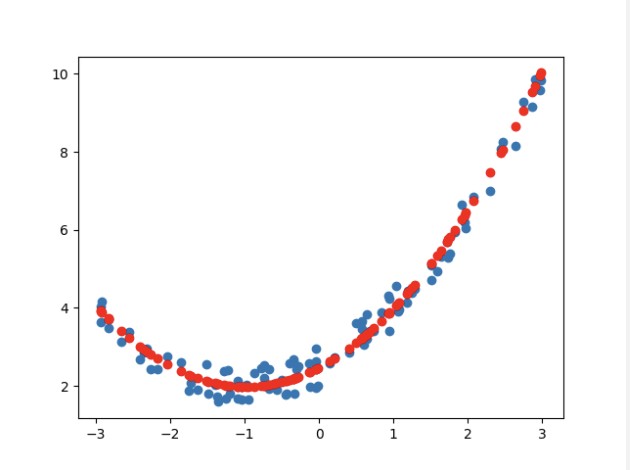
plt.scatter(X_test, y_test)
plt.scatter(X_test, y_pred, c='r')
plt.show()
print(r2_score(y_test, y_pred))
print(mean_squared_error(y_test, y_pred))
本节参考与文章:用 Pipeline 将训练集参数重复应用到测试集
https://wangguisen.blog.csdn.net/article/details/106885171?spm=1001.2101.3001.6650.2
- 发表于 2022-11-07 15:06
- 阅读 ( 2062 )
- 分类:python
