下载TCGA基因表达量文件,应该选Count,FPKM还是FPKM-UQ ?
下载TCGA基因表达量文件,应该选Count,FPKM还是FPKM-UQ ?
GDC中转录组的表达量文件有3种类型,分别对应着不同的定量方法。
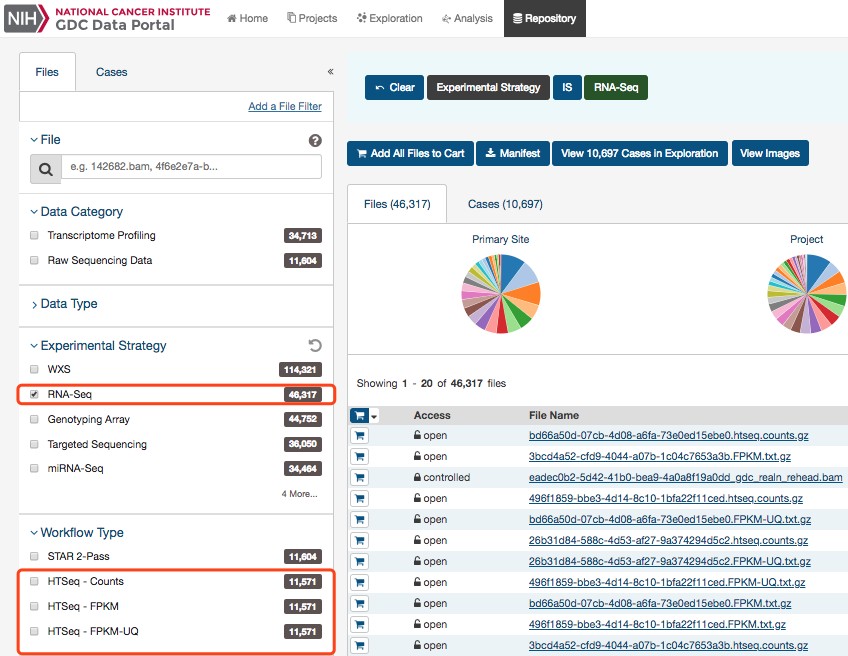
Counts 就不用说了,来看看FPKM和FPKM-UQ有啥差别,这个可以查看GDC的官方说明文档中的转录组分析部分,两者的计算公式:
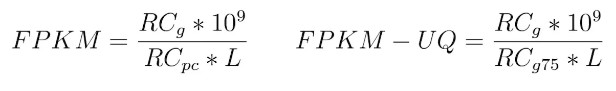
RCg: 比对到基因上的reads数量
RCpc: 比对到所有编码蛋白基因上的reads数量
RCg75: 样品中75%分位对应的基因reads数目
L: 基因的长度,为外显子长度之和
以一个计算实例来说明两者的差别:
假设在样品1中Gene A 的相关统计信息如下:
1. Gene A的长度为:3000
2. 比对到Gene A上的reads数量:1000
3. 比对所有基因上的reads数据量:1,000,000
4. 样品1中覆盖75%基因的reads数:2000
那么,FPKM和FPKM-UQ的计算结果如下:
FPKM = (1,000)*(10^9)/[(3,000)*(1,000,000)] = 333.33
FPKM-UQ = (1,000)*(10^9)/[(3,000)*(2,000)] = 166,666.67
那么我们一般下载那种数据比较好呢?
如果是做差异分析的话,我建议采用counts ,毕竟有不少的差异分析的软件都是基于counts数。
如果是计算样品间的相关性,聚类等,那就可以采用均一化的FPKM,和FPKM-UQ。当然下载counts,之后进行标准化,也是可以的。
所以,一般下载counts会比较好一些。
如果你对TCGA数据挖掘有兴趣的话,可以学习我们的TCGA相关课程。
- 发表于 2018-06-15 14:55
- 阅读 ( 14417 )
- 分类:TCGA
