解决基因组当中蛋白质序列ID和gff中ID不一致的问题
解决基因组当中蛋白质序列ID和gff中ID不一致的问题
经常有小伙伴做基因家族分析时遇到gff里面的mRNA ID与蛋白或者cds 序列 ID不一致的问题: 导致程序报错
例如下面玉米的GFF里面的mRNA ID和基因组基因蛋白序列的ID不一致的问题;
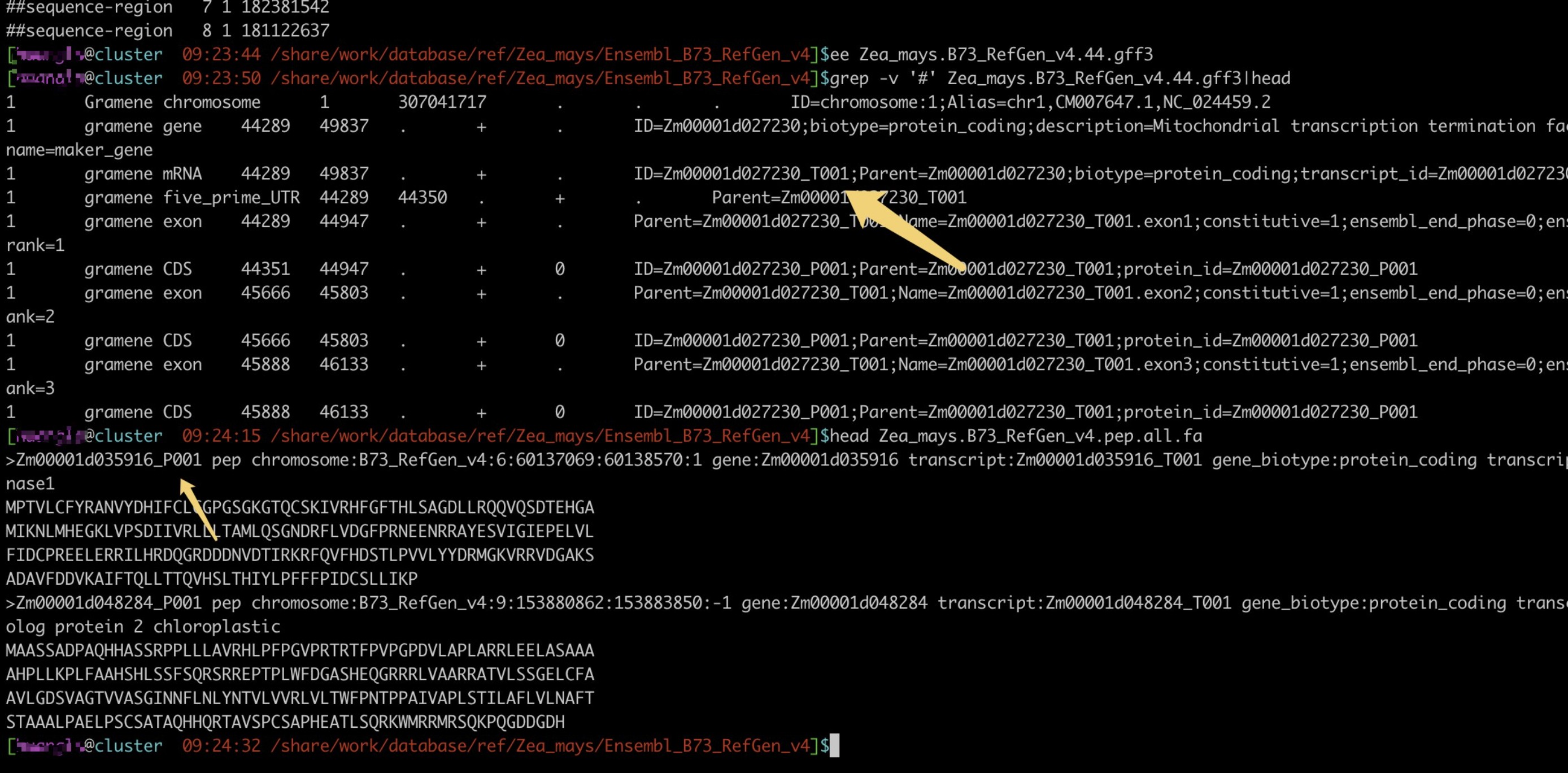
一劳永逸的彻底解决办法是,自己根据GFF信息,从基因组里面提取基因的蛋白序列和cds序列;这里给出代码:
# 设置文件路径和物种拉丁名,并运行
species=Zea_mays
genome=Zea_mays.B73_RefGen_v4.dna.toplevel.fa
gff=Zea_mays.B73_RefGen_v4.44.gff3 #以下代码不用修改,可直接运行
#保留蛋白编码基因
agat_sp_filter_feature_by_attribute_value.pl --gff $gff --attribute biotype --value protein_coding -t '!' -o $species.protein_coding.gff3
#保留最长转录本
agat_sp_keep_longest_isoform.pl --gff $species.protein_coding.gff3 -o $species.longest_isoform.gff3
#Ensembl 下载的基因组 会在基因和mRNA ID前面加gene: 和 transcript:这里给去掉
sed -i 's/gene://' $species.longest_isoform.gff3
sed -i 's/transcript://' $species.longest_isoform.gff3
#提取cds序列
/share/work/biosoft/TransDecoder/latest/util/gff3_file_to_proteins.pl --gff3 $species.longest_isoform.gff3 --fasta $genome --seqType CDS >$species.cds.fa
#提取pep序列
/share/work/biosoft/TransDecoder/latest/util/gff3_file_to_proteins.pl --gff3 $species.longest_isoform.gff3 --fasta $genome --seqType prot >$species.pep.fa
以上代码可以在基因家族分析镜像 2.0中运行: omicsclass/gene-family:v2.0
注意,以上命令会将基因组读入内存,因此电脑内存不足的可能会报错,有条件的可以购买我们的大内存云服务器:https://study.omicsclass.com/
- 发表于 2023-04-06 09:38
- 阅读 ( 9017 )
- 分类:基因家族分析
