R语言中转换成dummy dummy-variables 虚拟变量
了解虚拟变量
DUMMY VARIABLE
在数据分析中,利用回归模型来寻找变量间的关系是广泛应用的一种数据分析方法。通常情况下,回归分析中变量都是定量数据,原因是模拟回归需要样本数据。然而在实际的操作中,模型中只考虑定量变量是不全面的。因为很多经济现象不仅受一些定量数据的影响,还会受到一些定性数据的影响。比如自然灾害、战争等特殊时期对经济的影响,特殊政策的颁布对经济产生的影响等。
如果能确定某一研究结果存在这种定性影响,那么仅仅用定量数据对被解释变量进行解释显然是不够严谨的,很可能对模型的预测结果产生很大偏差。但由于定性数据是不等距的,不符合回归分析中对自变量要求,如果直接把定性数据直接引入线性回归模型,结果很难解释,且容易存在很大偏差,此时则需要对定性因素(或分类变量)进行虚拟编码(dummy coding),将其转为虚拟变量,可以考虑将虚拟变量引入回归模型来解决此类问题。
那么我们在数据分析时,面对这种情况应该如何操作呢?因此,本期内容主要就这一问题进行展开,为大家整理了“虚拟变量及其应用”的相关资料分享给亲爱的小伙伴们~
基础知识
(一)基本概念
虚拟变量 ( Dummy Variables) 又称虚设变量、名义变量或哑变量,用以反映质的属性的一个人工变量,是量化了的自变量,通常取值为0或1。引入虚拟变量可使线形回归模型变得更复杂,但对问题描述更简明,一个方程能达到两个方程的作用,而且接近现实。
例如,反映文化程度的虚拟变量可取为:1:本科学历;0:非本科学历
(二)模型中引入虚拟变量的作用
1、分离异常因素的影响:例如分析我国GDP的时间序列,必须考虑"**"因素对国民经济的破坏性影响,剔除不可比的"**"因素。
2、检验不同属性类型对因变量的作用,例如工资模型中的文化程度、季节对销售额的影响。
3、提高模型的精度,相当于将不同属性的样本合并,扩大了样本容量(增加了误差自由度,从而降低了误差方差)
(三)虚拟变量数量的确定
虚拟变量的数目不是越多越好,也不是越少越好。虚拟变量的数目设定规则:若定性因素有互斥的类型(或者水平)m个,在考虑截距项的模型中按照需要引入m-1个虚拟变量,如果引入m个虚拟变量就会产生完全的多重共线性。在不考虑无截距项的模型中,定性因素有互斥的类型(或者水平)m个,按照需要引入m个虚拟变量,不会导致完全多重共线性。
(四)虚拟变量的0和1的选取原则
虚拟变量取1或0的原则,应从分析问题的目的出发。一般地,在虚拟变量的设置中:基础类型、肯定类型取值为1;比较类型,否定类型取值为0。
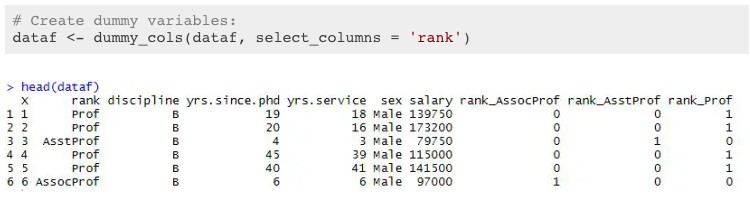
这里有一篇文章如何在R语言中创建虚拟变量:https://www.marsja.se/create-dummy-variables-in-r/
- 发表于 2023-12-21 15:11
- 阅读 ( 1830 )
- 分类:GWAS
