blast 中的e-value值如何理解?
对e-value值的by chance 进行解释
最近在使用blast进行序列检索的时候,有两个比较重要的评价标准,即Max score和e-value:
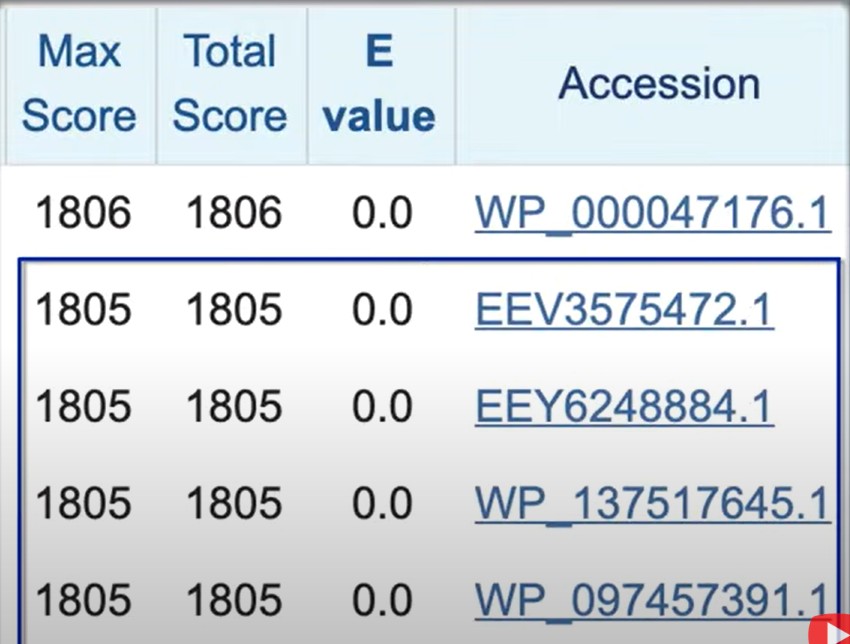
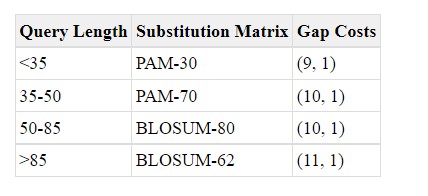
score值很好理解,即根据不同的打分矩阵,对序列间的匹配程度进行打分,得分矩阵比如PAM和BLOSUM(氨基酸):
 e-value值的概念看起来就相对的比较模糊了,官方的定义是e-value:the number of hits you expect to see by chance/false positive .
e-value值的概念看起来就相对的比较模糊了,官方的定义是e-value:the number of hits you expect to see by chance/false positive .
对于定义里面的“by chance”,也就是随机情况下指的是什么意思不是很了解,随后查阅了一下文献,是这样解释的:
by chance means:
①real but non-homologous sequences
②real sequences that are shfflued to preserve compositional properties
③sequences that are generated randomly based on a DNA or protein sequence model
也就是说要求匹配到的序列之间具有生物学意义上的联系,即具有同源性。
- 发表于 2024-01-23 16:32
- 阅读 ( 3027 )
