R语言按列合并文件,并保持其中一个文件的原有顺序
1.join函数;2.创建新的顺序变量;3.inner_join函数
使用R语言对两个文件按列合并时,我们一般会用merge函数,
而merge函数会对该列的顺序重新排序,即对rowname重新排序
在实际操作中,有时候我们需要根据某一文件的顺序生成文件,merge函数无法实现
举个例子:
# 数学成绩
math <- data.frame(name=c("小明","小红","小亮","小欣"),math=c(76,84,64,88))
# 英语成绩
english <- data.frame(name=c("小亮","小欣","小明","小红"),english=c(95,77,59,42))
用merge()函数将两个数据框合并,最终生成结果顺序发生了变化,且无论math和english顺序是否变化,得到的是一样的结果
c <- merge(math,english)
c
name math english 1 小亮 64 95 2 小明 76 59 3 小欣 88 77 4 小红 84 42
d <- merge(english,math)
d
name math english
1 小亮 64 95
2 小明 76 59
3 小欣 88 77
4 小红 84 42
想保持文件的原有顺序(以math文件的姓名列为例),有以下几种方法
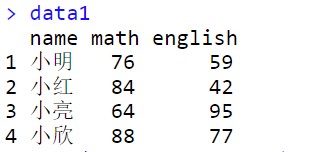
1. join函数
data1<- plyr::join(math,english,by="name")
2.创建一个新的顺序变量
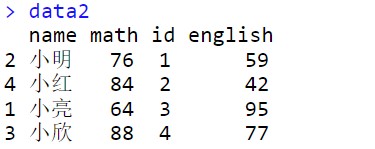
创建一个新的变量,它给出math中的行号顺序。合并数据之后,就可以根据这个变量对新的数据集进行排序。
##按照math的name顺序合并两个数据集
math$id <- 1:nrow(math)
data2 <- merge(math,english, by = "name")
data2 <- data2[order(data2$id), ]
3.inner_join函数
data3 <- inner_join(math,english)

参考:https://blog.csdn.net/JjinYyi/article/details/108476583
https://blog.csdn.net/ouyangk1026/article/details/122363301
- 发表于 2024-01-30 17:49
- 阅读 ( 2155 )
- 分类:R
