R语言基础入门—R语言概述与安装!
R语言简介
1.什么是R语言
R语言是于1991年由新西兰奥克兰大学的Robert Gentleman 和 Ross Ihaka 及其他志愿人员开发的一个语言系统。因为这两个开发者的名字都是以字母R开头,所以就叫做R语言,R是用于统计分析、绘图的语言和操作环境。
2.为什么选择R语言
1)专门为生物统计而生的语言R的开发最初是要解决生物统计方面的问题,创始人之一的Robert Gentleman,就是一位生物学家。所以,R最开始就是用来做生物统计,这个人后来又开发Bioconductor包,专门用来收录与高通量测序生物数据分析相关包的数据库。目前Bioconductor已经收录了大量的生物数据分析相关的包,包括做转录组差异分析的常用包DEseq2,edgeR,芯片数据分析相关的limma、affy包等等,目前已经收录了1741包(截止2019.6.30)。当然R语言不止只有Bioconductor,还有CRAN也收录了很多R包。2)开源免费1995年, Martin Michler 说服Ross 和Robert在GNU这个许可证下授权,这使得R成为了一个免费的软件。R软件是一款非常优秀的数据分析软件,市面上也有很多其他流行的统计和绘图软件,例如微软公司的Excel,SAS,IBM 公司的SPSS,Stata,S-PLUS以及Matlab等。这些软件当中大多都是商业软件需要支付高昂的费用才能使用,而R语言则是免费的,R是一个全面的统计研究平台,提供了各式各样的数据分析技术,几乎可以完成任何类型的数据分析工作,并且R拥有顶尖的绘图功能,可以绘制非常专业精美的图形。3)优秀的绘图功能R语言为统计而生,而我们生物数据分析当中很多地方都需要用到统计分析,所以说掌握R语言是学生物学生的基本技能。数据在统计分析之后,最重要的就是要把结果可视化的展示出来,而R语言也有非常强大的绘图功能,很多高水平杂志当中漂亮的图都是应用R语言绘制的。
3.R语言入门书籍推荐
1)学习R
2)R语言编程艺术 3)R语言实战读完前两本书,结合例子学习更佳:
3)R语言实战读完前两本书,结合例子学习更佳:
R语言安装环境搭建
1.安装R语言解释器
R语言解释器可根据自己的操作系统选择下载安装,选择中国的镜像地址下载速度快:
地址 说明
https://mirrors.tuna.tsinghua.edu.cn/CRAN/ TUNA Team, Tsinghua University
http://mirrors.tuna.tsinghua.edu.cn/CRAN/ TUNA Team, Tsinghua University
https://mirrors.ustc.edu.cn/CRAN/ University of Science and Technology of China
http://mirrors.ustc.edu.cn/CRAN/ University of Science and Technology of China
https://mirror-hk.koddos.net/CRAN/ KoDDoS in Hong Kong
https://mirrors.eliteu.cn/CRAN/ Elite Education
https://mirror.lzu.edu.cn/CRAN/ Lanzhou University Open Source Society
http://mirror.lzu.edu.cn/CRAN/ Lanzhou University Open Source Society
https://mirrors.tongji.edu.cn/CRAN/ Tongji University
具体下载地址:目前最新版本4.4.0(2024.04.23),如果要下载最新版本,可以到上面网址查找最新版本下载。最新版本下载地址:https://mirrors.tuna.tsinghua.edu.cn/CRAN/
- windows 下载地址:https://cran.r-project.org/bin/windows/
- 苹果系统 Mac os:https://cran.r-project.org/bin/macosx/
- Linux 系统 :https://cran.r-project.org/bin/linux/
2.Rstudio 编辑器安装(推荐)
Rstudio 为R语言的专业编辑器,有代码的提示,高亮显示等等功能,强烈推荐使用,初学者根据自己的操作系统下载RStudio Desktop 免费版本就可以:官方下载网址:https://www.rstudio.com/products/rstudio/download/
常见问题解答:
Rstudio中文乱码:http://www.omicsclass.com/article/294
R扩展包安装
1.CRAN 上的扩展包安装——The Comprehensive R Archive Network
#加快安装速度设置镜像
install.packages("ggplot2",repos="http://mirrors.tuna.tsinghua.edu.cn/CRAN/")
#可以设置全局镜像加快安装速度,推荐全局设置镜像,一些依赖包都可以默认这个镜像下载,安装更快:
local({r <- getOption("repos")
r["CRAN"] <- "http://mirrors.tuna.tsinghua.edu.cn/CRAN/"
options(repos=r)})
install.packages("ggplot2")
#多个包一起安装:
install.packages(c("poppr", "mmod", "magrittr", "treemap"), repos = "http://mirrors.tuna.tsinghua.edu.cn/CRAN/",dependencies = TRUE)
2.Bioconductor上扩展包安装
网站:https://www.bioconductor.org/
#设置国内的镜像地址,加快安装进度
options(BioC_mirror="https://mirrors.tuna.tsinghua.edu.cn/bioconductor")
#安装bioconductor中的包管理BiocManager,if如果没有安装则安装一下
if(!requireNamespace("BiocManager", quietly = TRUE)){
install.packages("BiocManager")
}
#安装bioconductor中DESeq2这个包
BiocManager::install("DESeq2")
3.github上扩展包安装
github上的包可以用devtools或者remotes包安装:
install.packages("devtools")
devtools::install_github('cole-trapnell-lab/monocle3')
install.packages("remotes") # 首先安装 remote 包
remotes::install_github("GuangchuangYu/nCov2019") # 尝试安装
安装笔记见:http://www.omicsclass.com/article/106R包载入:
library(ggplot2)
#或者
require(ggplot2)
#加载包时,如果报错说明包没有安装成功
R语言基础概念
下面介绍一下R语言中的常量、变量和数据结构这些基础概念。1.常量常量是指直接写在程序中的值。R语言基本的数据类型有数值型, 逻辑型,文本(字符串)。支持缺失值,有专门的复数类型。数值型常量包括整型、单精度、双精度等,一般不需要区分。支持科学计数法,写法如下:
123
123.45
-123.45
-0.012
1.23E2
-1.2E-2
字符型常量用两个双引号或两个单引号包围,字符型支持中文。如下所示:
"Li Ming"
'Li Ming'
"李明"
'李明'
国内的中文编码主要有GBK编码和UTF-8编码, 有时会遇到编码错误造成乱码的问题,MS Windows下R程序一般用GBK编码,但是RStudio软件采用UTF-8编码。在R软件内字符串一般用UTF-8编码保存。逻辑型常量只有TRUE和FALSE,也可用T和F简写。
TRUE
FALSE
T
F
缺失值用NA表示。统计计算中经常会遇到缺失值,表示记录丢失、因为错误而不能用、节假日没有数据等。除了数值型,逻辑型和字符型也可以有缺失值, 而且字符型的空白值不会自动辨识为缺失值,需要自己规定。R支持特殊的Inf值,这是实数型值,表示正无穷大,不算缺失值。复数常量写法如下:
2.2 + 3.5i
1i
2.变量程序语言中的变量用来保存输入的值或者计算得到的值。在R中,变量可以保存所有的数据类型。变量都有变量名,R变量名必须以字母、数字、下划线和句点组成, 变量名的第一个字符不能取为数字。变量名是区分大小写的, y和Y是两个不同的变量名。变量名举例: x, x1, X, cancer.tab, clean_data, diseaseData。用<-赋值的方法定义变量。<-也可以写成=,但是<-更直观。如
x <- 6.25
x = 6.25
R的变量没有固定的类型, 给已有变量赋值为新的类型, 该变量就变成新的类型, 但一般应避免这样的行为。R是“动态类型”语言, 赋值实际上是“绑定”(binding), 即将一个变量名与一个存储地址联系在一起, 同一个存储地址可以有多个变量名与其联系。3.数据结构R语言数据结构包括向量,矩阵和数据框,数组, 列表,因子等,主要是线性代数中的一些概念。数据中元素、行、列还可以用名字访问。最基本的是向量类型。向量类型数据的访问方式也是其他数据类型访问方式的基础。
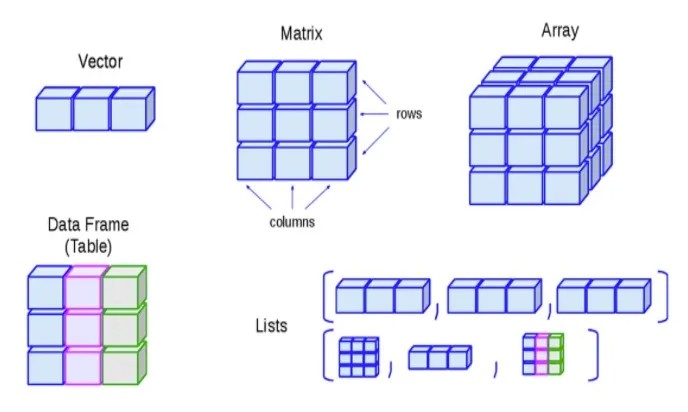
向量(Vector)
向量是一维的同质数据结构,即向量中的所有元素必须是相同的数据类型。向量可以是数值型、字符型或逻辑型等。
示例:
num_vector <- c(1, 2, 3, 4) # 数值型向量
char_vector <- c("A", "B", "C") # 字符型向量
log_vector <- c(TRUE, FALSE, TRUE) # 逻辑型向量
矩阵(Matrix)
矩阵是二维的同质数据结构,每个元素都必须是相同的数据类型。矩阵可以看作是扩展了的向量。
示例:
matrix_data <- matrix(1:6, nrow=2, ncol=3) # 创建一个 2 行 3 列的矩阵
数组(Array)
数组是多维的同质数据结构,可以看作是扩展了的矩阵。
示例:
array_data <- array(1:8, dim=c(2,2,2)) # 创建一个 2x2x2 的数组
数据框(Data Frame)
数据框是二维的异质数据结构,每列可以包含不同类型的数据。数据框类似于数据库中的表格,常用于存储数据集。
示例:
df <- data.frame(name=c("Alice", "Bob"), age=c(25, 30)) # 创建一个数据框
列表(List)
列表是一维的异质数据结构,可以包含不同类型的数据,包括向量、矩阵、数据框、甚至其他列表。
示例:
lst <- list(name="Alice", age=25, scores=c(90, 95, 88)) # 创建一个列表
因子(Factor)
因子用于表示分类数据,是带有标签的整数向量,常用于统计建模。
示例:
fac <- factor(c("male", "female", "female", "male")) # 创建一个因子
好了,今天小编就先给大家介绍到这里,下期我们会详细介绍每种数据结构。希望对您的科研能有所帮助!祝您工作生活顺心快乐!
参考:https://www.rpubs.com/huang2002003/1195822
- 发表于 2024-11-12 17:43
- 阅读 ( 935 )
- 分类:R
