三代转录组,当前你不可忽视的研究手段
在生物学研究中二代测序,尤其是转录组测序,仍扮演着重要的角色,但已经从曾经的刷文利器跌落神坛,短读长这个缺点也不断受到诟病。转录组学的研究由谁来挽救?答案就是三代测序技术—单分子全长转录组测序。该测序技术可以直接得到全长转录本,无需组装,克服了二代测序技术缺陷,必将开创转录组学研究的新篇章。
下面以一篇2017年11月1日发表在Gigascience(IF 6.871)上的四倍体咖啡的三代转录组文章详细阐释下三代转录组的应用。
研究目的及选材
作者在该项研究中重点关注了2个方面,一是咖啡因合成途径中基因Isoform 的多样性;二是以蔗糖合成基因为切入点研究多倍体系统转录的多样性。
阿拉伯咖啡占世界咖啡贸易的70%,具有很高的商业价值,阿拉伯咖啡为异源四倍体,祖先种是C. canephora 和 C. eugenioides,目前仅有C. canephora基因组被破译,该实验旨在通过三代转录组揭示四倍体阿拉伯咖啡转录组本的多样性及得到一个较好的表达基因参考序列。
材料:阿拉伯咖啡按未成熟、中度成熟、成熟3个发育阶段,每个阶段随机选择5棵咖啡树,在上端和下端树冠分别取5枚咖啡豆备用,每棵10枚咖啡豆,取果皮,单独提取后等量混合为一个样品,用于测序,每个样品重复三次。咖啡豆成熟度如下图:

建库片段长度:0.5-10K
测序平台:Pacbio RSII
数据产出:共产出2,618,905raw reads,滤除300以下reads,除去线粒体、叶绿体及核糖体RNA后最终得到95995条高质量Isoforms ,对这些Isoforms 在4个数据库中进行了功能注释。
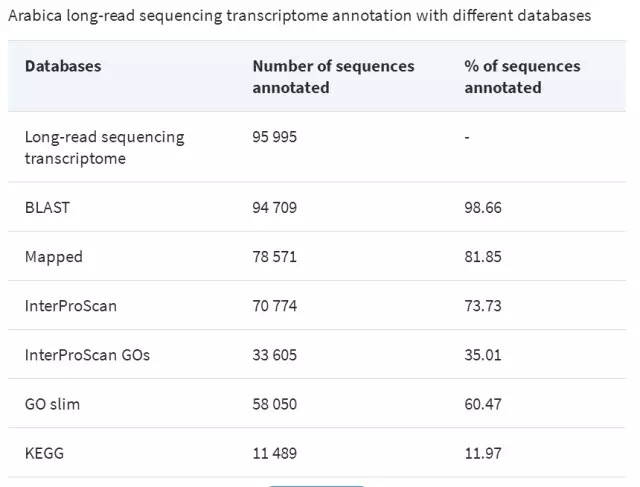 与之前咖啡EST及Coffea canphora基因信息完整度有了很大提升。
与之前咖啡EST及Coffea canphora基因信息完整度有了很大提升。
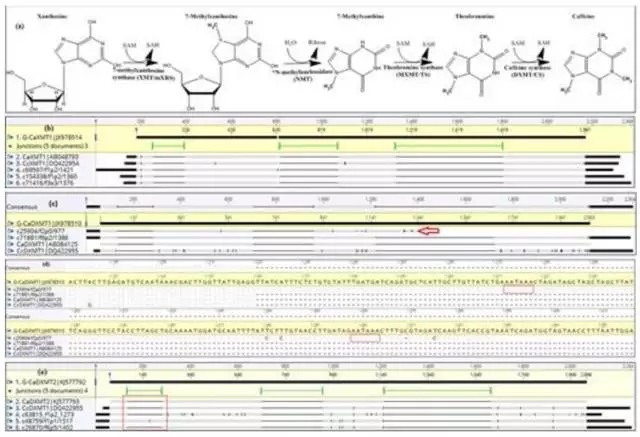
1.咖啡因合成途径中基因Isoforms 的多样性
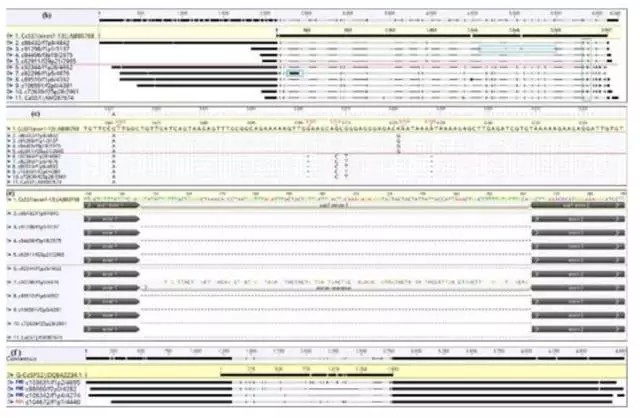
作者通过已公布的咖啡因合成基因序列为参考,通过blast比对发现有25条Isoforms与咖啡因合成基因同源性很高,经过进一步筛选10条Isoforms被认定为候选咖啡因合成基因,包括3个XMT1的变异体,MXMT1的1个,DXMT1的2个,DXMT2的3个变异体。
这10个基因囊括了除XMT2 外的负责合成咖啡因的所有基因。与之前公布的阿拉伯咖啡和罗布塔斯咖啡基因序列相比,10个基因的序列在5'UTR区均有所延伸,8个基因在3'区有延伸,延伸最长达136bp,9个基因长度甚至超过了之前公布的基因组上的基因长度,另有基因发生可变聚腺苷酸化事件和可变剪接事件。
本次检测到的XMT1、 MXMT1和 DXMT2 的序列 与其祖先种中果咖啡中转录组本有更好的一致性,这表明这些基因转录可能来自于中果祖先种所提供的那部分遗传物质;相反XMT2 、 MXMT2 和DXMT1 所表现出的一致性要差一些,所以这几个基因的转录组可能来自于另一半基因组(C.eugenioides)。
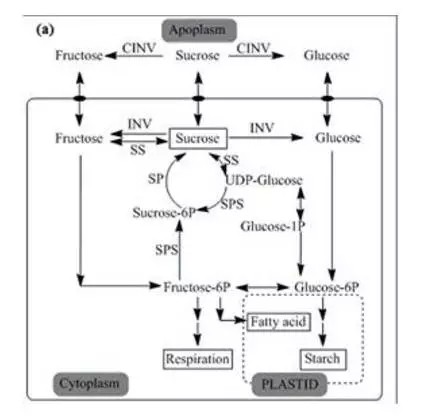
2. 蔗糖合成基因研究多倍体系统转录的多样性
蔗糖合成酶1(SS1)有9个变异体,在本次结果中这9个变异体序列均在5'区有所延伸, 并且在这9个基因的5'区鉴定出了12个ORF,并且ORF数量与5'区长度呈正相关,5'UTR区的多样性在咖啡品质及其抗逆性上可能起到关键作用。分析发现9个蔗糖合成酶中有4个与中果咖啡中蔗糖合成酶序列表现出很高的一致性,这说明该4个SS1基因的转录组应该来源于中果祖先种基因组部分;另外5个SS1基因则表现出较多的变异,推测其来源于C. eugenioides祖先种基因组部分。
小结及启示
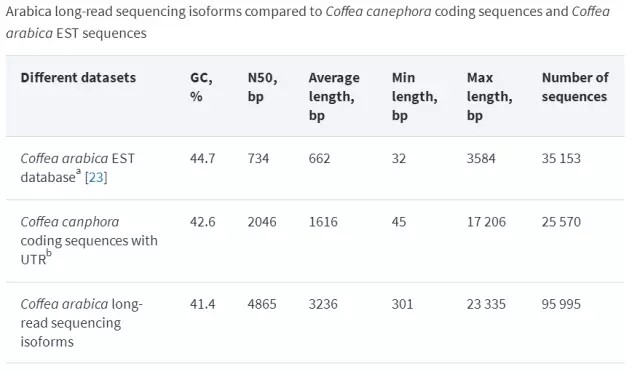
与其他已公布的咖啡基因数据相比,本次实验结果无论是isoforms的数量还是长度都表现出了巨大的优势,并且GC含量亦较低,这说明三代转录组在转录本序列测序方面具备更大的优越性。
通过blast比对,约9.7%和3.8%的isoforms分别与C.canephora的CDS序列和阿拉伯咖啡的基因片段不匹配,这说明了本次检测到的isoforms具有很高的多样性,而这种多样性也只有通过全长转录组测序才能准确地捕捉到。
同时,C.canephora的CDS序列和阿拉伯咖啡的基因片段分别有26.1%和18.9%与本次得到的isoforms无法对应,这也有可能是由于不同试验取材不同造成的。
参考文献:
Cheng B, Furtado A, Henry R J. Long-read sequencing of the coffee bean transcriptome reveals the diversity of full-length transcripts[J]. Gigascience, 2017, 6(11):1-13.
1. 转录组数据理解不深入?图表看不懂?点击链接学习深入解读数据结果文件,学习链接:转录组(有参)结果解读;转录组(无参)结果解读
2. 转录组数据深入挖掘技能-WGCNA,提升你的文章档次,学习链接:WGCNA-加权基因共表达网络分析
3. 转录组数据怎么挖掘?学习链接:转录组标准分析后的数据挖掘
5. 更多学习内容:linux、perl、R语言画图,更多免费课程请扫描下方二维码:

- 发表于 2018-04-22 12:11
- 阅读 ( 4572 )
- 分类:转录组
