一键搞定批量序列提取TBtools!
用基因ID提取其序列很简单,ctrl+F找到ID对应的序列,ctrl+C、ctrl+V就好了,少量基因的还OK,但是如果有几百个甚至上千个ID,手指会不会很酸爽?
这里墙裂推荐一个软件,功能很强大,就是TBtoo...
用基因ID提取其序列很简单,ctrl+F找到ID对应的序列,ctrl+C、ctrl+V就好了,少量基因的还OK,但是如果有几百个甚至上千个ID,手指会不会很酸爽?
这里墙裂推荐一个软件,功能很强大,就是TBtools!今天主要讲它批量提取序列的功能(其他功能以后再说,你们也可以自己试试),这个软件需要在JAVA运行(选中软件,右键打开方式选择java)。
这个软件批量提取序列只需要四步:
1、输入序列文件
输入抽提ID对应序列所在的fasta文件,例如这个物种所有的cds序列的fasta文件。可以直接在下图较长方框内输入fasta文件所在路径和文件名,例如:C:\Users\10792\Desktop\aaa.fasta;或者点击右侧黄色方框输入fasta文件
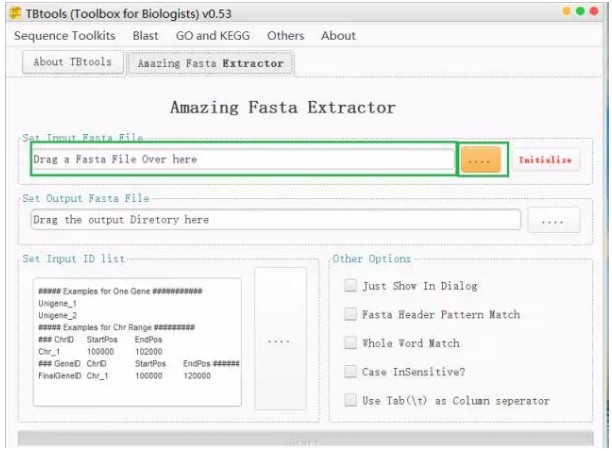
2、输入ID
ID的格式是每个ID占一行输入ID所在的文件,可以直接在下图方框内输入ID,或者点击右侧黄色方框导入ID文件,注意:输入的ID要和fasta格式">"后面的一致,例如:ID是AT1G51270,fasta如下图才可以将ID对应的序列提取出来。
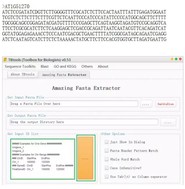 3、导出结果存放文件
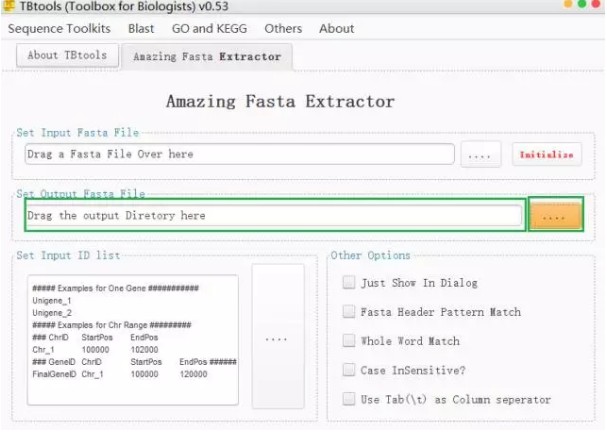
3、导出结果存放文件
先建一个空的的fasta文件(例如建一个txt文件,将后缀txt改为fasta,就是一个fasta文件了),然后在下图较长方框内输入这个fasta文件所在路径及文件名,例如:C:\Users\10792\Desktop\out.fasta;或者点击右侧黄色方框导入这个结果存放的fasta文件。
4、运行
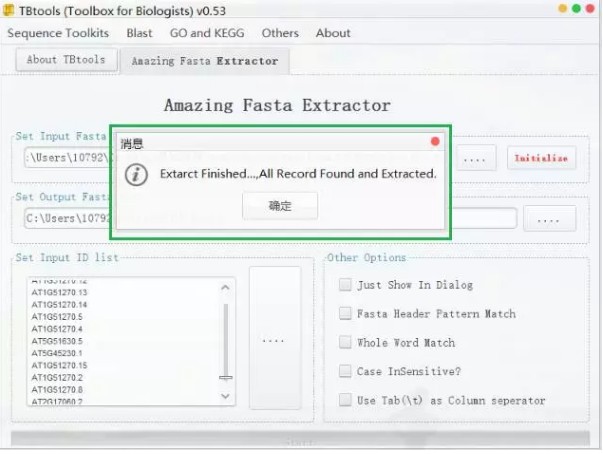
先点击Initialize初始化处理,待最下面的Start方框变蓝色,点击Start运行。
弹出下图方框就运行完了,速度很快(亲测,拿200多个ID提取序列,只用了不到1秒!!!)。
- 发表于 2018-04-22 19:08
- 阅读 ( 33726 )
- 分类:软件工具
