2019年转录组文章该怎么写?
2018已经成为过去,2019年的转录组文章到底该怎么写?难or易?
这里小编给您带来一篇2019年1月21日发表在BMC Plant Biology(影响因子3.93,中科院分区二区)上的转录组测序文章。该篇文章样品不多,思路明了,分析简单,没有过多的复杂的补充实验,值得借鉴;下面我们一起看一看这篇2019年转录组文章是怎么写的!

本篇文章采用红豆杉作为研究材料,主要目的是研究紫杉烷类物质在不同红豆杉品种中差异积累的机制。
1、实验材料:
T.media、T.mairei、T.cuspidata三个品种,每个品种准备了5棵独立的树。
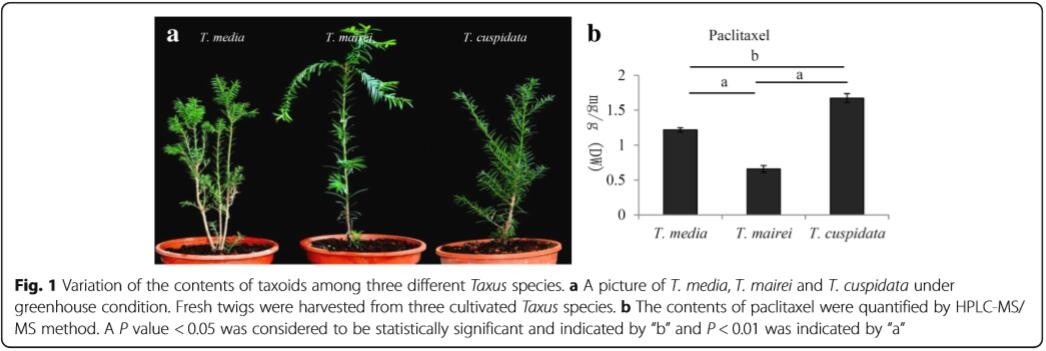
2、使用HPLC-MS/MS测定紫杉醇含量,检测发现,T.cuspidata的紫杉醇含量最高,T.mairei的紫杉醇含量最低。
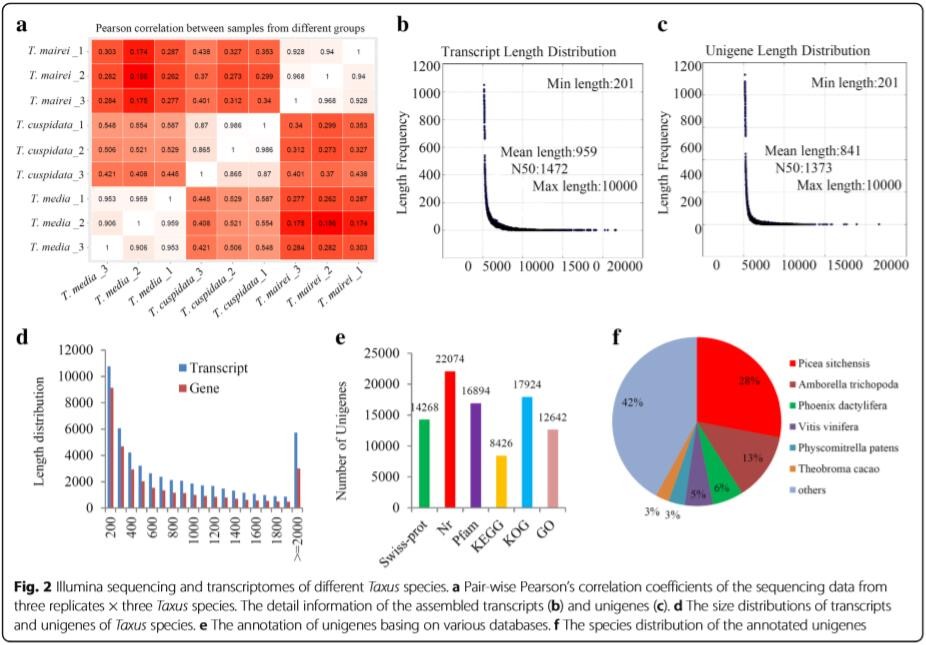
3、每个品种3个生物学重复,共9个样品进行转录组测序,共得到67.49Gb测序数据,相关性分析表明,三个生物学重复间相关性高重复好(见下图a)。
同时,由于是无参物种,所以需要进行转录本组装和unigene库构建,作者采用了两种组装模式:以基因鉴定和表达分析为目的时,采用的是合并组装,以序列分析为目的时采用了单独组装。
对这些unigenes进行了功能注释:Swiss-Prot、Nr、Pfam、KEGG和KOG。
通过PCA分析发现,三个树种分为了两组,其中T.media和 T.cuspidata较为相近。
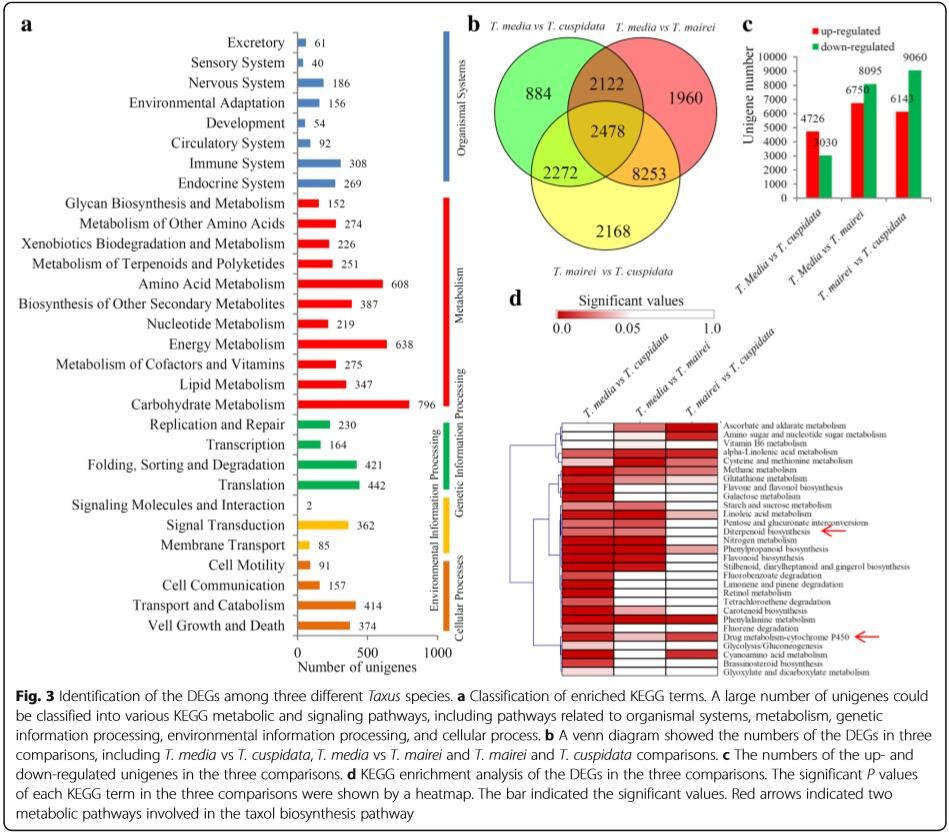
4、作者通过KEGG富集分析发现,氨基酸代谢、能量代谢以及碳水化合物代谢途径的富集程度最高。
同时,通过差异分析进一步统计了各个差异组合中富集程度较高的代谢通路。
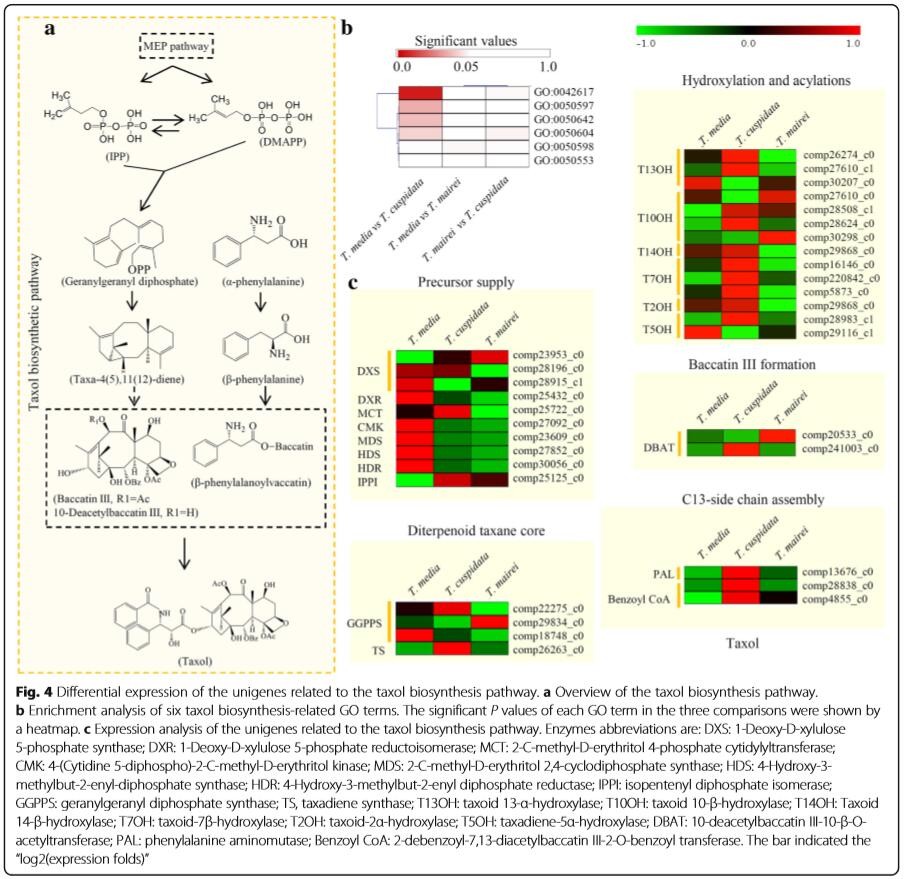
 5、作者进一步分析了紫杉醇的生物合成途径,然后根据GO注释结果进行了详细的分析,找出了参与紫杉醇生物合成每一步的GO terms,并进一步分析了相关的差异基因。
5、作者进一步分析了紫杉醇的生物合成途径,然后根据GO注释结果进行了详细的分析,找出了参与紫杉醇生物合成每一步的GO terms,并进一步分析了相关的差异基因。
6、通过三个树种单独组装的转录组数据,作者获得了12条MEP途径相关基因的全长序列。使用每种关建酶预测的三个肽段序列构建系统进化树,进一步发现,T.media 和T.cuspidata的相似度较高。
7、通过数据分析,作者发现了4个和茉莉酸(JA)途径相关的GO terms。进一步分析了这4个GO terms在各个差异组合中的差异情况。同时作者也测定了这三个树种的内源性的JA含量。
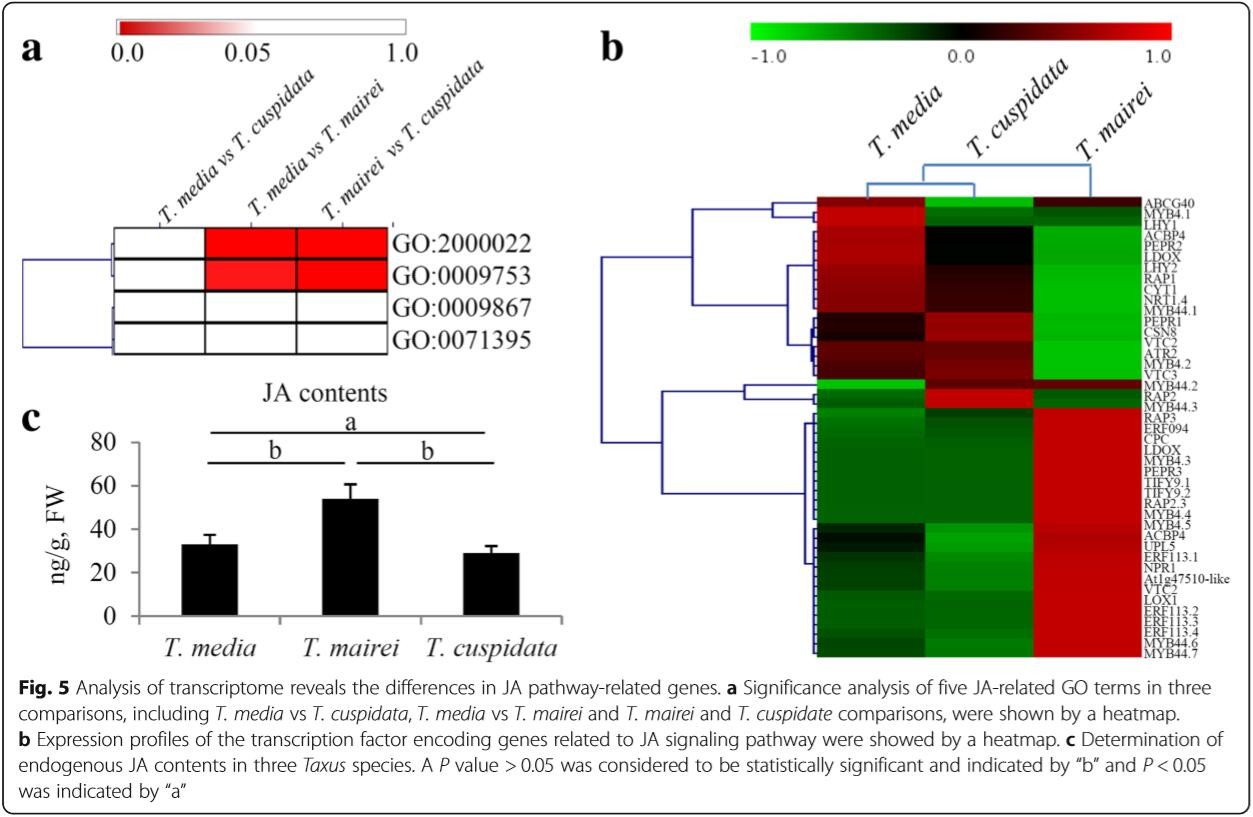
8、通过分析,作者共鉴定了736个TF编码的基因,主要和17个TF家族相关,包括MYB、ARF、WRKY等。
9、最后,作者结合前人的研究进展和自己的分析结果做了深入的讨论。一篇二区的转录组文章就完成了。
总的来说,作者的思路清晰明了,以紫杉醇生物合成途径为切入点,对涉及到该途径的pathway、差异基因、GO terms等都做了深入的分析。在补充实验方面,作者测定了紫杉醇的含量和内源性的JA含量,并没有过多的复杂的实验内容,这可以为广大转录组的初学者提供一些文章思路。
更多详细信息请下载原文查看!
需要文献原文的老师请关注“组学大讲堂”微信公众号,转发该文章至您的朋友圈并截图,然后在公众号对话框内发送截图证明并留言 “红豆杉” 即可获得原文献!(注意关键词需写全)。
更多生物信息课程:
1. 文章越来越难发?是你没发现新思路,基因家族分析发2-4分文章简单快速,学习链接:基因家族分析实操课程、基因家族文献思路解读
2. 转录组数据理解不深入?图表看不懂?点击链接学习深入解读数据结果文件,学习链接:转录组(有参)结果解读;转录组(无参)结果解读
3. 转录组数据深入挖掘技能-WGCNA,提升你的文章档次,学习链接:WGCNA-加权基因共表达网络分析
4. 转录组数据怎么挖掘?学习链接:转录组标准分析后的数据挖掘、转录组文献解读
5. 微生物16S/ITS/18S分析原理及结果解读、OTU网络图绘制、cytoscape与网络图绘制课程
6. 生物信息入门到精通必修基础课,学习链接:linux系统使用、perl入门到精通、perl语言高级、R语言画图
7. 医学相关数据挖掘课程,不用做实验也能发文章,学习链接:TCGA-差异基因分析、GEO芯片数据挖掘、GSEA富集分析课程、TCGA临床数据生存分析、TCGA-转录因子分析、TCGA-ceRNA调控网络分析
8.其他课程链接:二代测序转录组数据自主分析、NCBI数据上传、二代测序数据解读。

- 发表于 2019-01-29 11:24
- 阅读 ( 6343 )
- 分类:转录组
