R 语言赋值运算符区别:`<-` , `=`, `<<-`
R 语言赋值运算符:`<-` , `=`, `<<-`
<- 与 = 间的区别
<- 与 = 在大部分情况下是应该可以通用的。并且,相对于 <<- 运算符,它们的赋值行为均在它们自身的环境层(environment hierarchy)中进行。
R语言中,<- 与 = 这两个赋值运算符最主要的区别在于两者的作用域不同。大家可以从下面的例子感受一下。
好多好多人喜欢用的 =
貌似许多早期学习R的童鞋都比较喜欢使用 = 进行赋值。毕竟,简简单单的a = 5用起来比较符合大多数现有语言的习惯。
> rm(x) ## 如果变量 x 存在的话,删除此变量 > mean(x = 1:10) [1] 5.5 > x Error: object 'x' not found
在以上范例里,变量 x 是在函数的作用域里进行声明的,所以它只存在于此函数中,一旦运算完成便“消失”。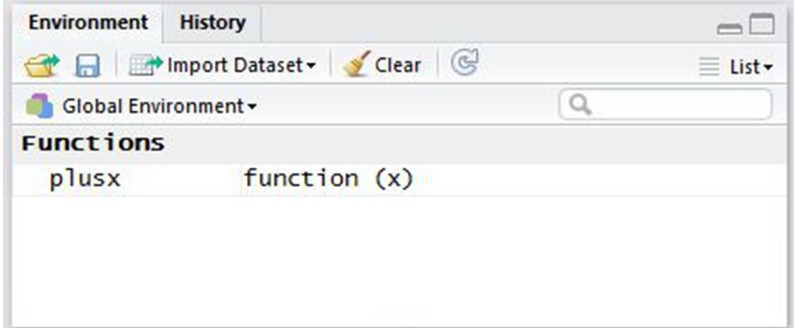
而对于 <-
使用 <- 的运算结果则如下:
> mean(x <- 1:10) [1] 5.5 > x [1] 1 2 3 4 5 6 7 8 9 10
这一次, Global Environment 里出现了 x 变量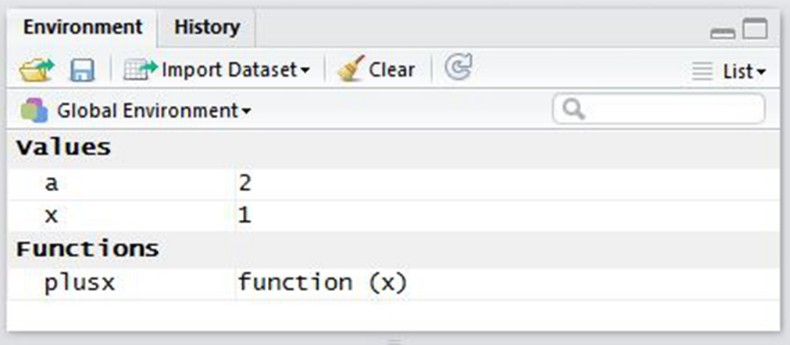
在什么情况下, <- 赋值会成立?
在以上代码里,你可能会认为计算机对上述语句进行的处理是“将 1:10 赋值给 x , 然后计算 x 的均值。”在某些语言里,计算机的确是如此处理的,比如说 C 。但是在R语言中,却不是这样的。见下例。
> a <- 1 > f <- function(a) return(TRUE) > f <- f(a <- a + 1); a [1] TRUE [1] 1
请注意,以上范例里, a 的值并没有改变!!在 R 中,在参数中进行赋值的变量只有在需要进行评估时才会改变其值。(也许,大家可以类比一下逻辑短路?1 < 0 && 2 == 1)这会导致程序里出现一些不可预期的结果并且降低代码可读性,所以并不推荐在函数参数里使用这一种赋值方式(事实上,函数参数弄那么复杂也是太无聊了了吧)
> a <- 1 > f <- function(a) { + if(runif(1)>0.5) TRUE + else a + } > f(a <- a+1);a [1] TRUE [1] 1 > f(a <- a+1);a [1] TRUE [1] 1 > f(a <- a+1);a [1] TRUE [1] 1 > f(a <- a+1);a [1] 2 > f(a <- a+1);a [1] TRUE [1] 2 > f(a <- a+1);a [1] 3
上述代码中,向函数 f() 传递传递参数 a <- a + 1 后,只有在随机数 runif(1) 小于0.5的时候,a 的值才会改变,即执行+1操作。否则传递TRUE值。因此,因为随机数 runif(1) 的随机性,每次调用函数 f()后 a 的值是不确定的。
BUT!
并不是说 <-看起来复杂所以就索性不用它了。事实上,正如上文所说,如果不是有人会这么无聊在R 语言里进行数据分析时用 <-弄个这么坑爹的函数参数,这个赋值号的意义本身是很清晰的。
<- 长得像箭头,实质上也是个箭头,如果觉得从右向左赋值让你觉得不爽的话,用 -> 甚至都是可以的。而那个传统的 = 号,在 R 里实质上是退化了的,其在规范的 R 语言代码里其实一般是作为为子集赋“name”的存在。
一个较为规范的赋值号使用方式应该是酱紫的。
> a <- list(hello = 1, world = 2 ) ##如果 <- 换成 = 得多混乱…… > a $hello [1] 1 $world [1] 2 > a$hello [1] 1 > a[["world"]] ## '$' 与 '[["..."]]'是两种不同的引用name的方式~~ [1] 2
<<— 运算符,向上一环境层写入变量
在 R 语言中,处在某一个环境层的代码都拥有读入上一环境层的变量的权限,但相反地,若只通过标准的赋值运算符 <- ,是无法向上一环境层写入变量的。若想在上一环境层进行赋值行为,即向上一层次写入变量,则需要用到 <<- (superassignment)运算符啦~
对非局部变量进行写入操作
看,灰机!
> plusx <- function(x){ + a <<- 1 + x + b <- 2 + x + x <- x * 2 + } > a Error: object 'a' not found > b Error: object 'b' not found > x <- 1 > plusx(x) > a [1] 2 > b Error: object 'b' not found > x [1] 1
分析一下函数two() 中的三个变量 x, a, b
- x:作为plusx()的实际参数,调用时其值1复制到形参 x ,但形参仍为局部变量,故作为全局变量的 x 值不变
- a:在调用函数plusx() 之前, 变量 a 和 b 是根本就不存在的。直到调用了plusx()后,a 才在出现。并且,由于plusx()的上一环境层即为顶层环境(Global Environment), 可直接在变量框内看见 a。
- b:为局部变量,正如上文所说, <- 进行的赋值仅在当前环境层进行。
此例表明, 通过 <<- 赋值符,plusx()函数在顶层环境写入了变量 a .
一些注意事项
一般说来, <<- 多用于在顶层环境中写入变量。然而需要注意的是,以 <<- 执行赋值时,会一直向上直至顶层进行变量查找。若在查找过程中寻找到该名称的变量,就会进行赋值操作。否则,将在顶层环境中创建变量并赋值。
> glob <- function(){ + d <- 5 + nxt1 <- function(){d <<- e + 1} + e <- 2 + nxt1() + d + } > glob() [1] 3 > d Error: object 'd' not found
此处,对 d 运用了 <<- 进行赋值时,由于nxt1()的上一环境层中出现了变量 d ,故赋值在glob()环境层进行,而非顶层(Global Environment)
对比以下代码:
> glob <- function(){ > + ##区别在这里,少了一行' d <- 5' + + nxt1 <- function(){d <<- e + 1} + e <- 2 + nxt1() + d + } > glob() [1] 3 > d [1] 3
此处,由于glob()环境中没有 d 变量的存在,在 nxt1() 中使用 <<- 赋值时变量 d 成为顶层变量。
- 发表于 2019-02-22 13:56
- 阅读 ( 3454 )
- 分类:R
