iTRAQ/TMT蛋白质组学分析基本知识点
iTRAQ和TMT的区别?蛋白质组学分析依赖参考基因组么?分组混标原则?
- 0
- 2
- 生信老顽童
- 发布于 2018-07-31 08:55
- 阅读 ( 15116 )
科研作图也需要会使用Adobe illustrator和Photoshop
科研作图也需要会使用Adobe illustrator和Photoshop,用好了这两个软件也会使你的文章配图增色不少,甚至事半功倍。
- 0
- 2
- omicsgene
- 发布于 2018-07-19 11:47
- 阅读 ( 8916 )
转录组差异基因为什么要进行聚类分析?
聚类分析用于判断差异基因在不同实验条件下的表达模式,将表达模式相同或相近的基因聚集成类,进而识别未知基因的功能或已知基因的未知功能,这些同类基因可能具有相似的功能,共同参...
- 0
- 2
- landy
- 发布于 2018-06-28 16:28
- 阅读 ( 16602 )
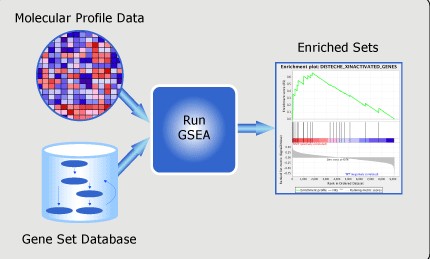
如何将GEO芯片注释文件整理成GSEA能使用的芯片注释文件?
将GEO数据库中的注释文件整理成GSEA软件可以使用的芯片注释文件
- 0
- 2
- landy
- 发布于 2018-06-22 15:01
- 阅读 ( 9220 )
Excel数据分析技巧之双因素方差分析
>>方差分析之双因素方差分析 小编在节前做过一期使用excel表进行单因素方差分析的推送,反响不错,小编也颇受鼓舞!但是,在许多情况下,单因素方差分析已经不能满足实际分析的需要。比...
- 1
- 2
- 生信老顽童
- 发布于 2018-06-20 10:29
- 阅读 ( 6056 )
TCGAbiolinks 错误 Error in value[[3L]](cond) : GDC server down, try to use this package later
TCGAbiolinks 错误 Error in value[[3L]](cond) : GDC server down, try to use this package later 排查
- 0
- 2
- microRNA
- 发布于 2018-06-20 09:47
- 阅读 ( 13508 )
aggregate对数据分组处理
利用aggregate对数据进行分组处理,包括分组求和,分组取均值,最大值,中位数等等
- 0
- 2
- Daitoue
- 发布于 2018-05-31 15:52
- 阅读 ( 8957 )
R语言计算平均值,中位数
Mean()求平均值 通过求出数据集的和再除以求和数的总量得到平均值 函数mean()用于在R语言中计算平均值。语法 用于计算R中的平均值的基本语法是 - mean(x, trim = 0, na.rm = FALSE, ...)...
- 1
- 2
- 安生水
- 发布于 2018-05-24 15:53
- 阅读 ( 13720 )
linux下替换文件中的换行符
之前在linux系统执行以下命令: ls file |xargs sed -i 's/\n//g' 然而却发现没有任何效果,百度之后发现 sed是按行处理文本数据的,每次处理一行数据后,都会在行尾自动添加trailing newline...
- 0
- 2
- 安生水
- 发布于 2018-05-24 10:35
- 阅读 ( 6606 )