就是如何通过ID号码查找他的大蛋白序列 ,然而其中的蛋白序列不知如何下载???
我们的这个脚本 会读入两个文件,一个提供ID列表,一个fasta文件,那么脚本会根据第一个文件的ID在第二个fasta文件里面对应ID的序列输出到第三个文件中。
如果觉得我的回答对您有用,请随意打赏。你的支持将鼓励我继续创作!

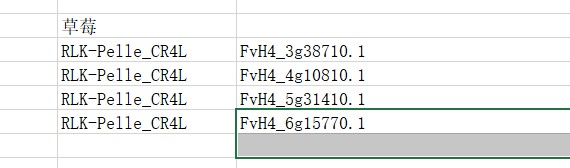 就是如何通过ID号码查找他的大蛋白序列 ,然而其中的蛋白序列不知如何下载???
就是如何通过ID号码查找他的大蛋白序列 ,然而其中的蛋白序列不知如何下载???