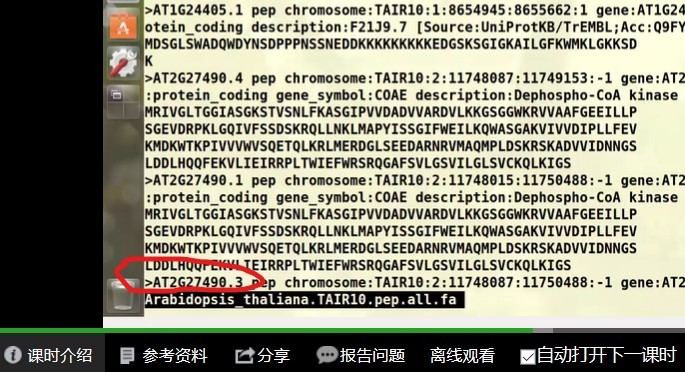
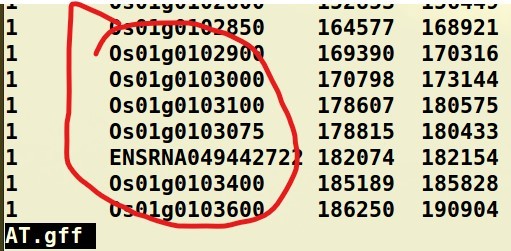
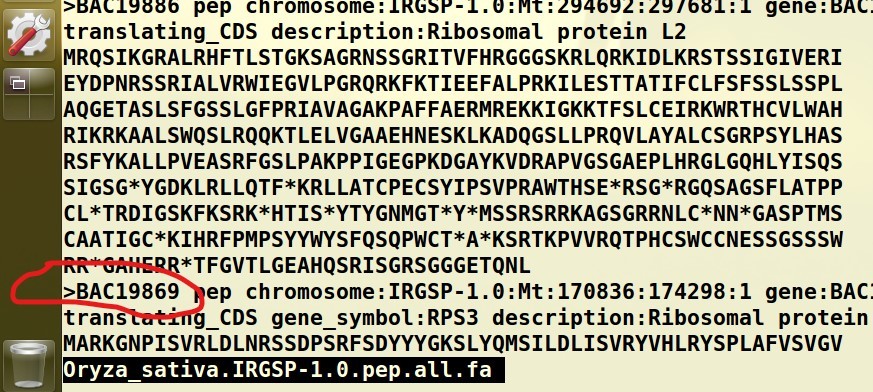
在课时14. MCScanX共线性分析基因家族加倍过程实操课中,已获得AT.gff文件,用它利用get_fa_by_id.pl来提取对应的蛋白质序列,发现提取不了,然后发现Oryza_sativa.IRGSP-1.0.pep.all.fa与拟南芥的数据库文件形式不同,没有对应的蛋白质ID,该如何解决?
拟南芥AT.gff
拟南芥.pep.all.fa
水稻AT.gff
水稻.pep.all.fa
仔细看视频,这里提取基因对应的一个转录本不是用的这个脚本:get_fa_by_id.pl
如果觉得我的回答对您有用,请随意打赏。你的支持将鼓励我继续创作!
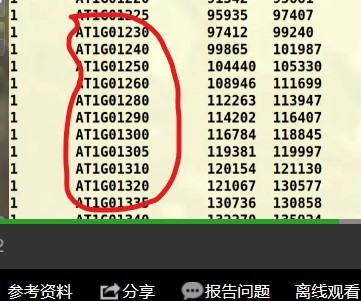 拟南芥.pep.all.fa
拟南芥.pep.all.fa