发现
问答
发起
提问
文章
文章
更多
专家
讲堂
话题
财富榜
商城
Toggle navigation
首页
(current)
问答
文章
视频课程
话题
商城
搜索
登录
注册
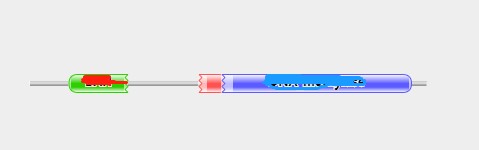
下图蓝色块是我想研究的结构域,按老师讲的脚本应该$a[9]==3,可是为什么提取不到这部分的结构域序列呢?请问哪里是不是错了呢?我该怎样调整呢?之前做的这个文件geneid2mRNAid.txt也是空的。
基因家族
domain
0 条评论
分类:
基因家族分析
请先
登录
后评论
默认排序
时间排序
1 个回答
omicsgene
- 生物信息
2019-11-10 19:16
擅长:重测序,遗传进化,转录组,GWAS
GFF文件里面的ID看看,和拟南芥蛋白质序列里面的ID是否一样,
怀疑你的ID里面的gene: 等没有删除;
请先
登录
后评论
×
如果觉得我的回答对您有用,请随意打赏。你的支持将鼓励我继续创作!
您需要登录后才可以回答问题,
登录
或者
注册
关注
1
关注
收藏
0
收藏,
3192
浏览
薄荷草
提出于 2019-11-10 17:10
相似问题
泛基因家族分析-数据准备
1 回答
如何自己制作泛基因组的pangene.list呢
2 回答
老师您好,我用plantcare分析顺式作用元件时,只要一上传文件就报错,上传文本(一条序列)的话能正常出结果,不知道这是什么情况
0 回答
一个基因家族包含两个结构域,对应interpro数据库两个hmm模型文件,请问怎么同时鉴定包含以上两个结构域的家族成员?
0 回答
购买的基因家族课程过期了,docker以及里面的基因家族分析包还是镜像,都不能用了吗?
2 回答
老师您好,做完蛋白序列多序列比对后,分析基因家族的保守位点,怎么判断那段保守位点指的哪个氨基酸活性位点呢,然后画出像文献中这样的图
1 回答
×
发送私信
发给:
内容:
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因: