
这个问题可以写个perl脚本或者python脚本完成,分别用bioperl或者biopython包处理fasta文件会很方便,有相应课程;
perl求助,基因ID的对应替换perl脚本怎么写
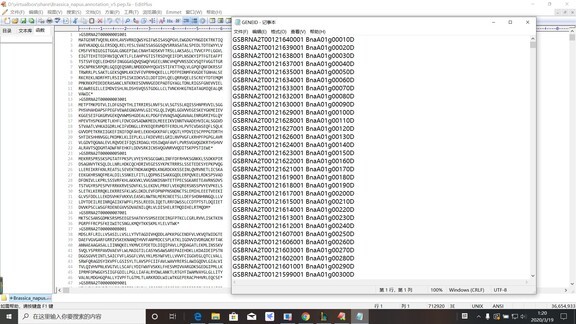
如图,想要将gene Alisa对应的Bna基因ID对应替换上去,perl脚本该怎么写。。
#!/usr/bin/perl ;
#usage:perl repalce.pl list.file fa.file out.file
open LIST,$ARGV[0];
open FAFILE,$ARGV[1];
open OUT,">$ARGV[2]";
undef $/;#
$in=<FAFILE>;#
study $in;
$/="\n";#
while(<LIST>){
chomp;
my($new,$old)=split;
$in=~s/$old/$new/;
}
这个是网上的perl,out文件是空白的。。求老师看一下
