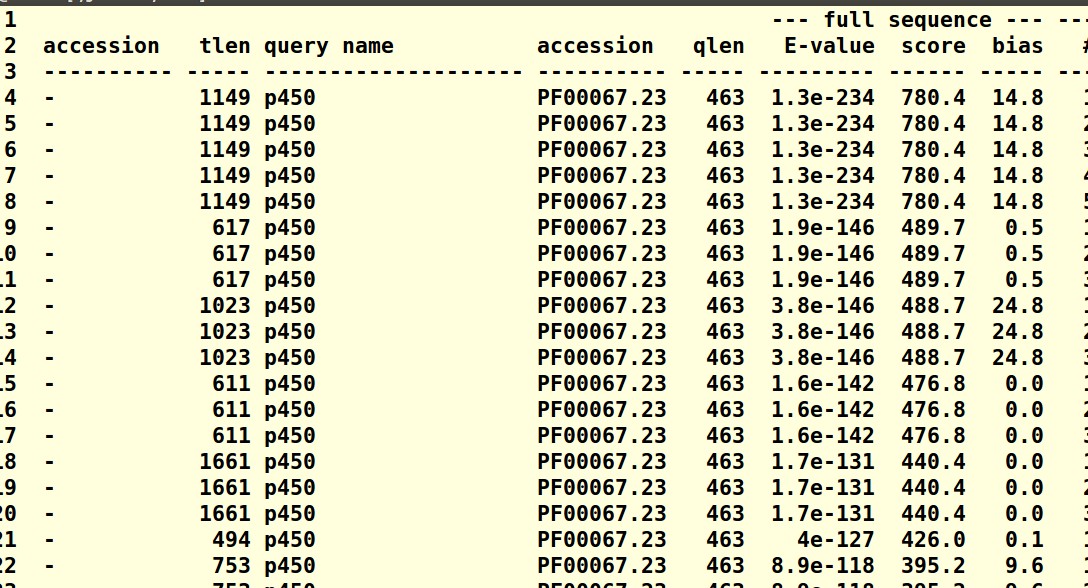
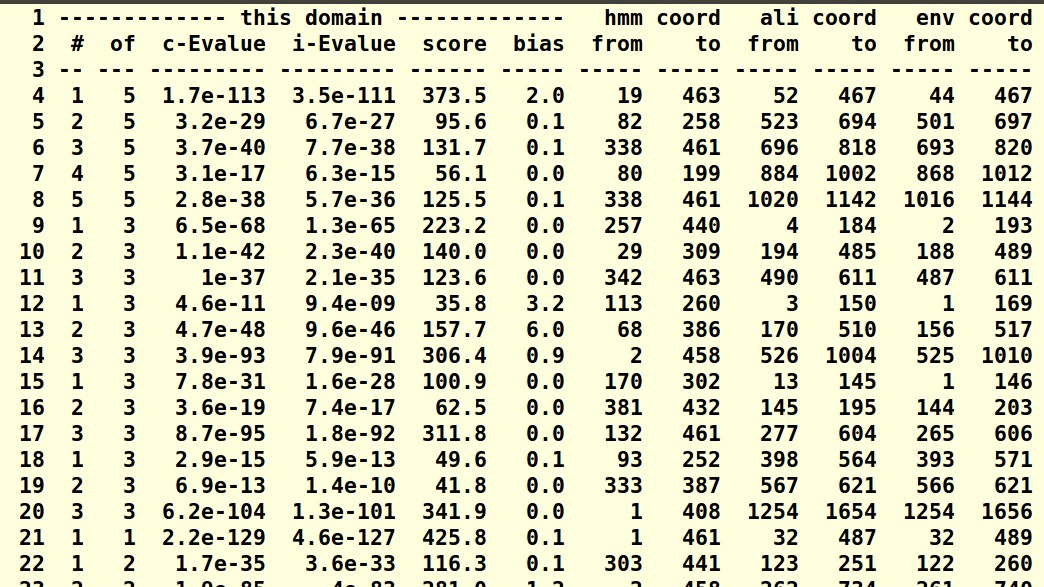
要建立自己的模型,选择可靠的,这些不完整的手动删掉就可以;
如果觉得我的回答对您有用,请随意打赏。你的支持将鼓励我继续创作!
再请问一下,删除这些不完整的有没有标准呢?比如说完整率达75%以上?我查文献的话,blast方法是有人用75%的匹配率来筛选。谢谢