10 代谢物分子注释结果的筛选
回答问题即可获得 10 经验值,回答被采纳后即可获得 15 金币。
非靶向代谢组学数据,progenesis QI软件的下机数据有两部分,一个measurements的定量文件和一个identifications的定性文件。
问题是这样的:
在定量文件里,compound列的每个值是唯一的,但在定性文件里,compound列与注释得到的分子名称列compound ID和description是一对多的关系,需要让compound与注释结果成一对一的形式,这个应该咋筛选?我知道的方法是按score值选取数值最大的注释结果,但是score值也有多个相同的,您看这个表
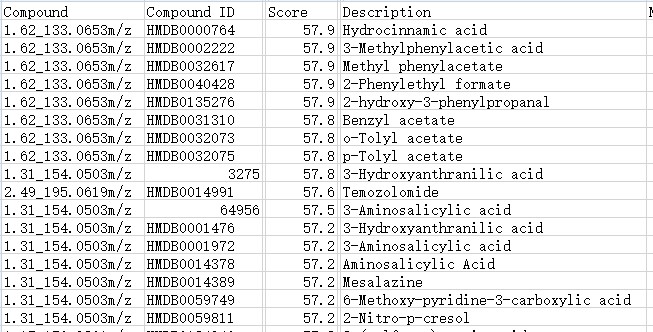 另外想请问各位老师,做进一步的代谢物通路富集一定需要确定代谢物分子的唯一注释结果嘛?
另外想请问各位老师,做进一步的代谢物通路富集一定需要确定代谢物分子的唯一注释结果嘛?
拜托各位老师解答下这两个问题,谢谢大家