发现
问答
发起
提问
文章
文章
更多
专家
讲堂
话题
财富榜
商城
Toggle navigation
首页
(current)
问答
文章
视频课程
话题
商城
搜索
登录
注册
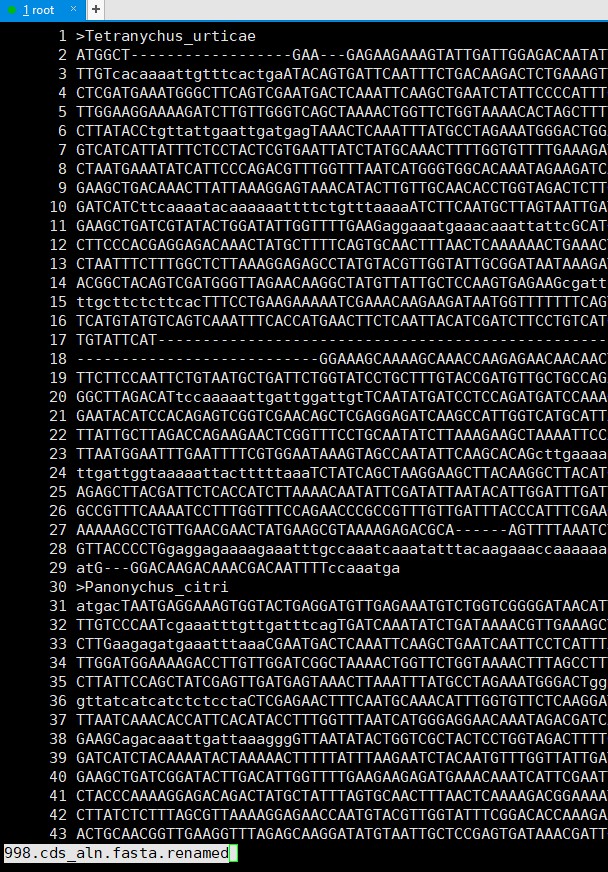
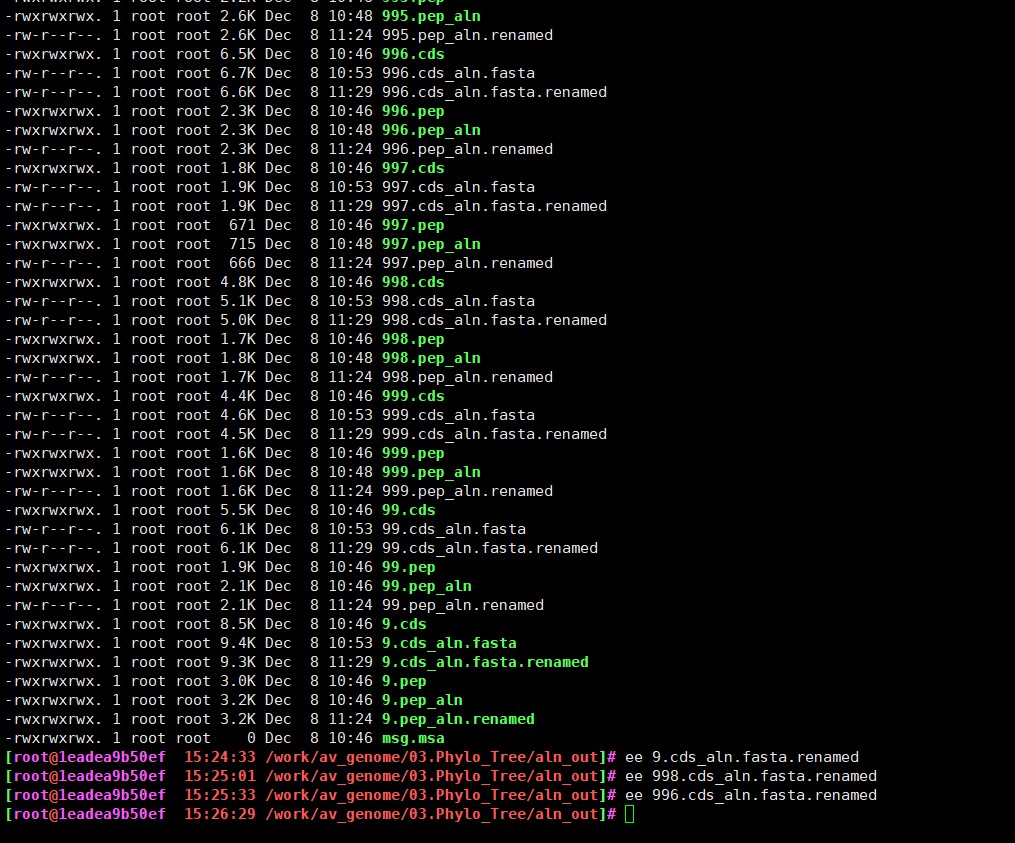
老师运行“ls aln_out/*.cds_aln.fasta |while read a;do sed -r 's/([A-Za-z]+_[A-Za-z]+)_.*/\1/g' $a > $a.renamed;done”后得到的结果single_copy.cds_msa.fasta是空的文件夹是空的,但是提取pep序列运行是正确的,这怎么解决呀
比较基因组
0 条评论
分类:
基因组学
请先
登录
后评论
默认排序
时间排序
1 个回答
omicsgene
- 生物信息
2023-12-08 16:19
擅长:重测序,遗传进化,转录组,GWAS
你需要用seqkit合并数据之后才可以得到这个结果;
查看一下,是否有空的比对结果;
请先
登录
后评论
×
如果觉得我的回答对您有用,请随意打赏。你的支持将鼓励我继续创作!
您需要登录后才可以回答问题,
登录
或者
注册
关注
1
关注
收藏
0
收藏,
1635
浏览
欢乐马
提出于 2023-12-08 15:39
相似问题
动植物比较基因组分析实操中基因组的版本信息
2 回答
使用docker镜像中的OrthoFinder.py检测单拷贝直系同源基因分析报错
2 回答
使用OrthoFinder时单拷贝基因很少,能说说用OrthoFinder结果里的低拷贝基因去建树吗
1 回答
老师请问,这种OG0000.。。代表的基因家族扩增还是收缩问题,他们的具体名称在哪里对应查找,比如OG000044代表钙粘蛋白基因家族,还是什么家族有名称吗?
1 回答
老师我做比较基因组的时候,准备文件阶段时用ncbi 下载的基因组跑不出来cds和蛋白质文件,麻烦老师您看一下
1 回答
ParaAT比对结果产生空的cds_aln.fasta文件
1 回答
×
发送私信
发给:
内容:
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因: