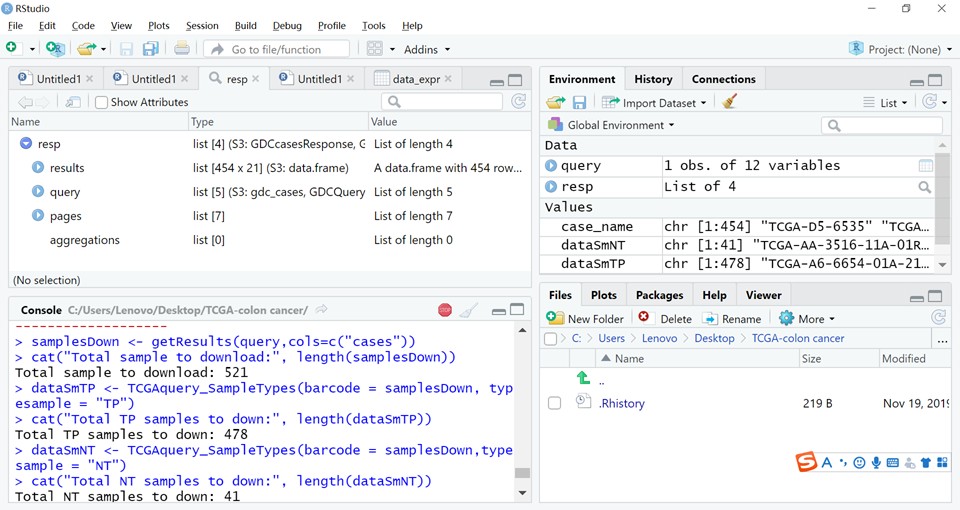
问题一:按课上老师教的筛选方法,网页上cases和file数量为何不一致(456和521),老师课上是一致的。
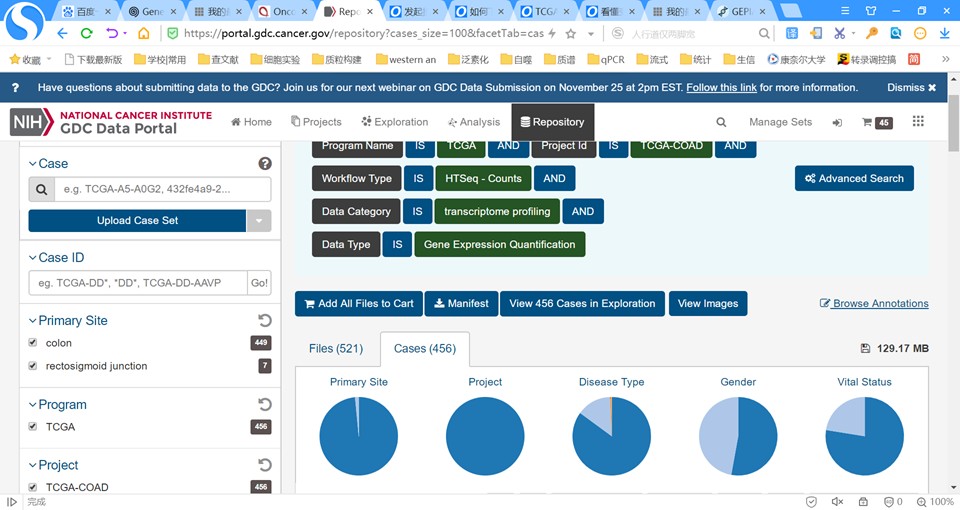
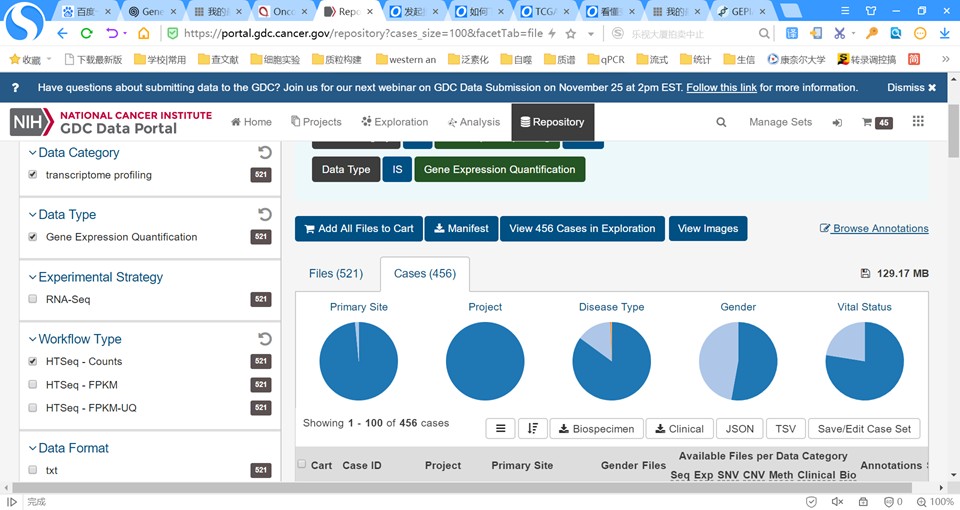
问题二:按老师的代码,样本总量不等于肿瘤+正常总和,为什么呢?
query <- GDCquery(project = "TCGA-COAD",data.category = "Transcriptome Profiling",data.type = "Gene Expression Quantification", workflow.type = "HTSeq - Counts",legacy = FALSE)