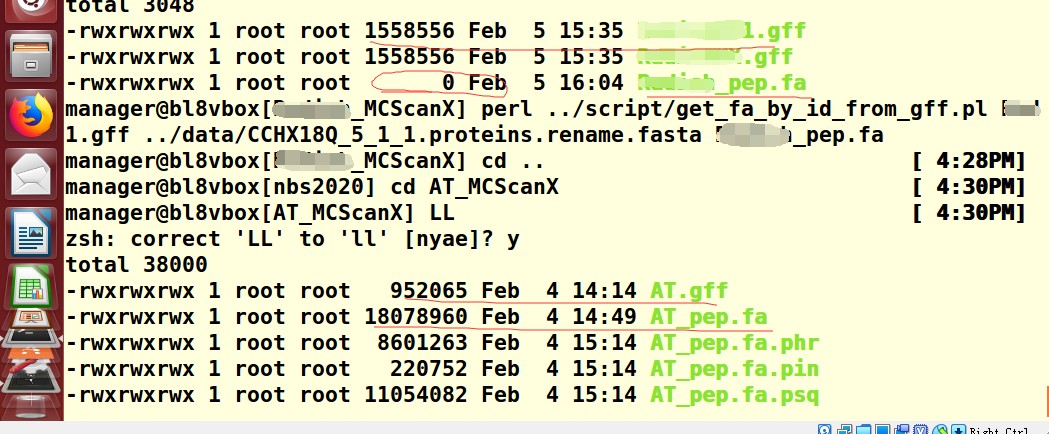
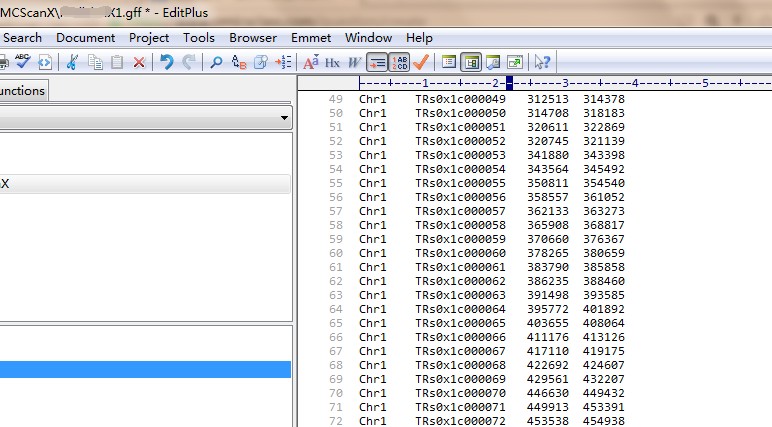
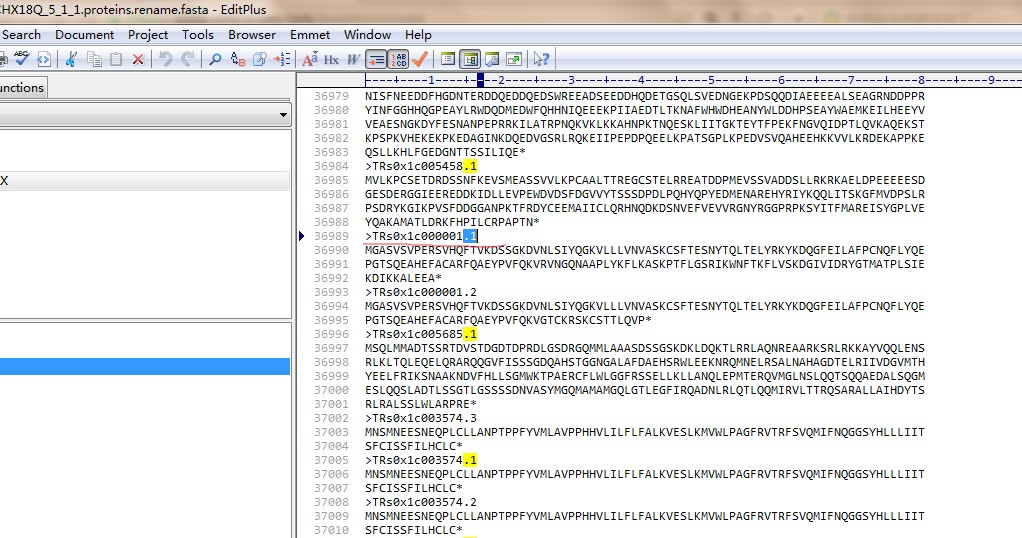
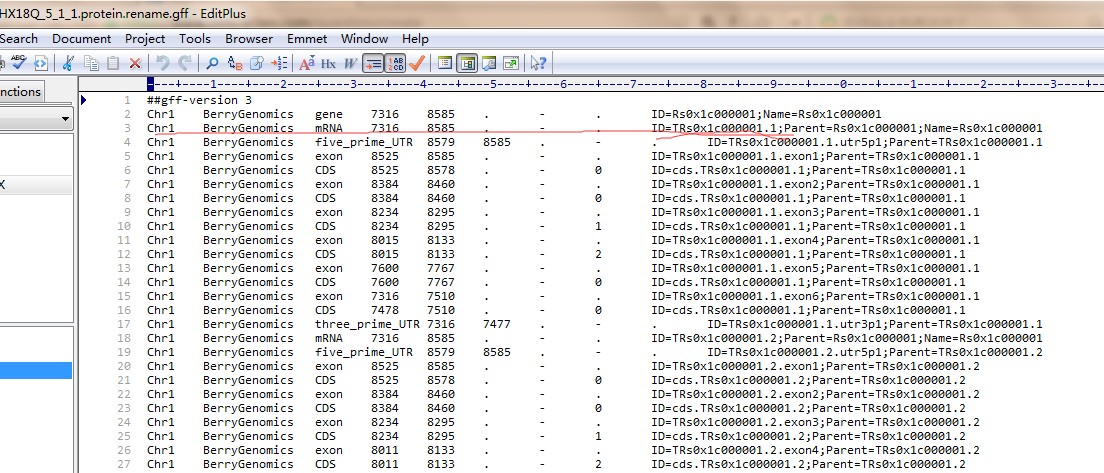
跟拟南芥一样,也是转录本第一个是在基因名后面加的.1,为什么提取不了蛋白序列呢
我看了一下蛋白序列文件中的转录本ID都是后面加的.1, 跟拟南芥的差不多啊,为啥提取不出来呢
拟南芥的可以成功,你再对比一下输入文件内容,是否写错;我看看你输入的gff文件和你查看的gff文件不一样
如果觉得我的回答对您有用,请随意打赏。你的支持将鼓励我继续创作!