5 老师,使用非ensemble数据库的蛋白质序列和基因组染色体fasta文件脚本要怎么进行修改呢?
最近在做油菜相关基因家族的相关工作,ensemble数据库里的pep和toplevel文件下载之后解压总是提示unexpected end of file,

就从其他数据库下载了pep和toplevel的文件,
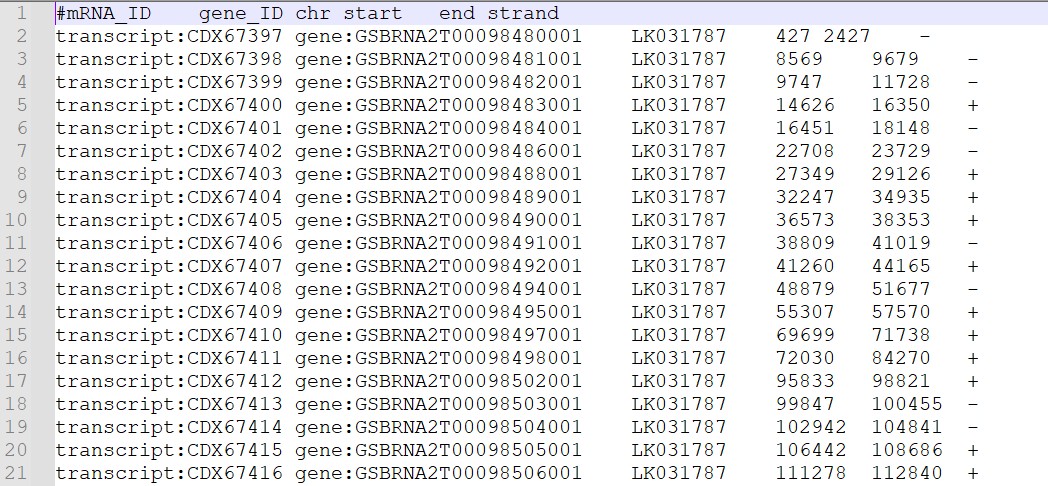 在除重复的hmmer搜索的转录本ID,多个转录本ID保留一个作为基因的代表的时候,得到了异常的结果,请问我是应该如何修改脚本,或者整理来自其他数据库的序列信息呢?
在除重复的hmmer搜索的转录本ID,多个转录本ID保留一个作为基因的代表的时候,得到了异常的结果,请问我是应该如何修改脚本,或者整理来自其他数据库的序列信息呢?
最佳答案 2022-02-05 22:30
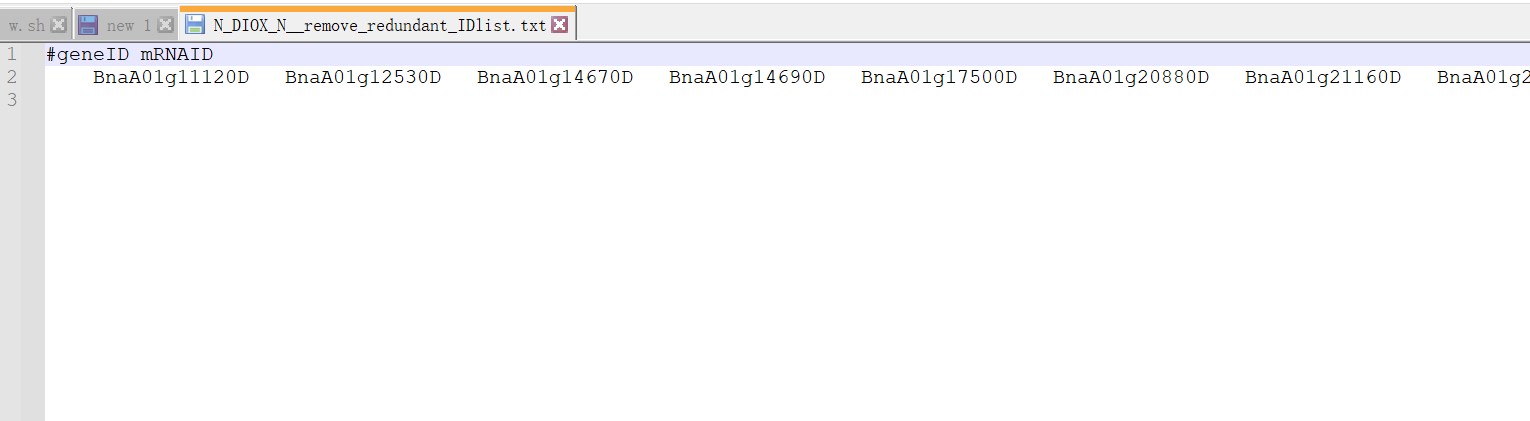
你再看看视频课程,GFF里面的mRNA ID要和蛋白里面的ID一致;
你需要提前吧gene: 等删除一下;
解压文件报错,是文件不完整,你再重新下载一下
如果觉得我的回答对您有用,请随意打赏。你的支持将鼓励我继续创作!
